


首页财产阐发评论ai正文 中门对于狙,这下真的AI春晚了 凌晨2点Anthropic更新Claude Opus 4.6,OpenAI同时发布GPT-5.3 Codex,两者跑分各有胜败,产物功效也各有进级,行业影响庞大。 2026-02-06 10:05 ·微信公家号:数字生命卡兹克数字生命卡兹克 数字生命卡兹克 AI投资人解读· Claude Opus 4.6跑分亮眼,于多范畴体现精彩,产物功效显著进级,如1M上下文窗口等,价格未变;GPT-5.3 Codex编程评测领先,能自立介入开发历程,可及时互动,运行速率更快。 · 行业竞争激烈,模子更新快,需连续存眷机能变化;政策羁系或者影响模子成长;算力成本、数据安全等也存于挑战。 总结:两款新模子各有上风,揭示出强盛潜力,但行业竞争与相干危害并存,建议连续跟踪评估其于差别场景的运用效果和成长态势。内容由AI天生,仅供参考
于全网翘首以盼的等了两天以后,于凌晨2点。
Anthropic的新模子Cluade Opus 4.6正式更新了。
我说真话,我是真的近来由于AI圈这些模子及产物,熬夜熬的有点扛不住了。
但实在最颠最绝望的是,20分钟以后,OpenAI也发了新模子。。。
GPT 5.3 Codex也来了。
这尼玛,真的是中门对于狙了。
要了亲命了。。。
这两模子都还有是患上看,由于以前GPT及Claude险些就是我最经常使用的维二最主力的模子,GPT-5.2用来做各类各样的搜刮及事实核查还有有研究还有有编程改BUG,Opus 4.5做创作及主力编程。
此刻,两个都来了。
太刺激了。
一个一个说吧。
一. Claude Opus 4.6
此次Anthropic实在不止发了Claude Opus 4.6,还有有一个很好玩的工具,Agent Teams,还有有关在Excel及PPT插件的更新。
先说Claude Opus 4.6。
每一次有新模子发布,各人第 一反映就是看跑分。
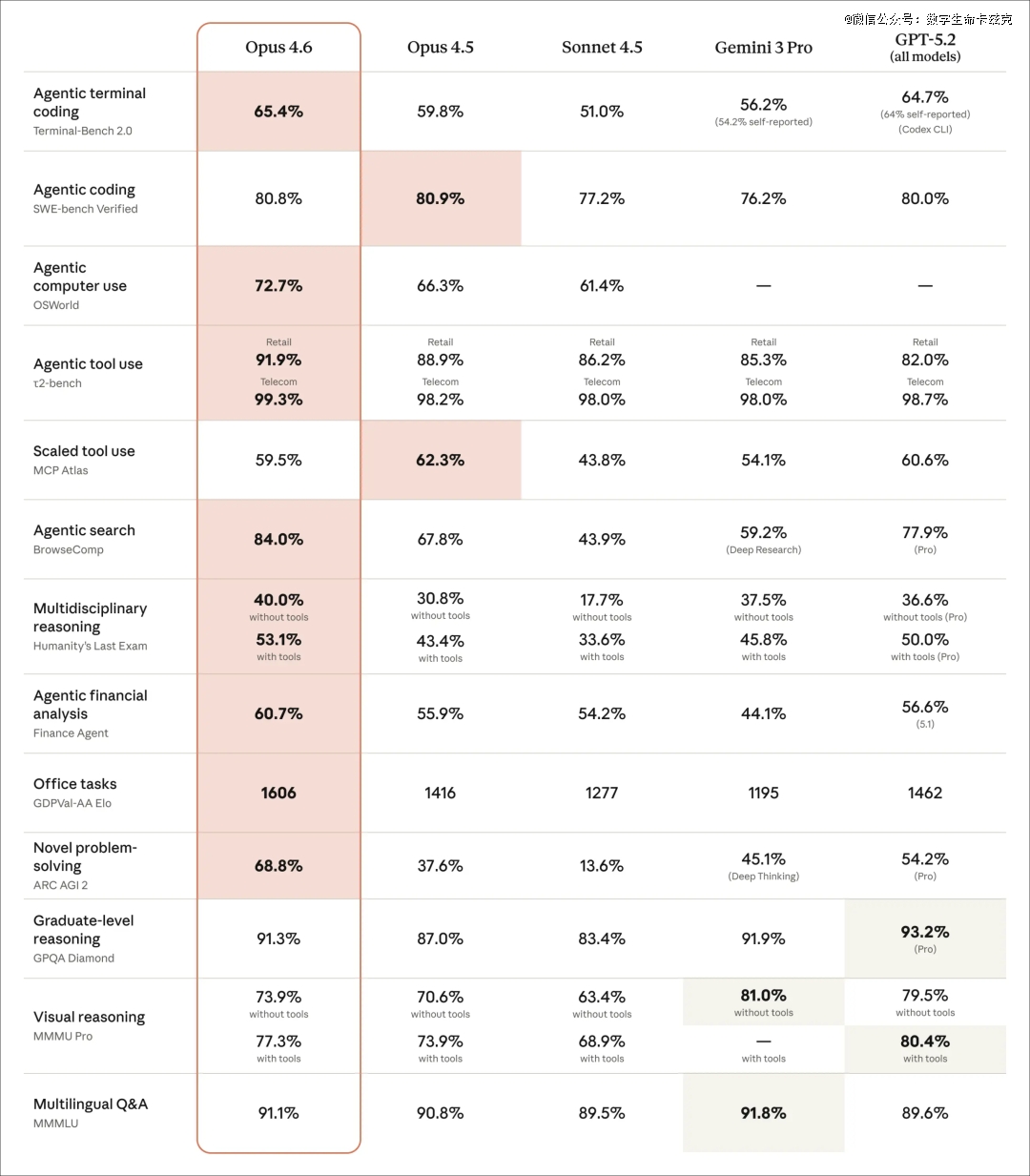
此次Opus 4.6的跑分确凿很美丽,我挑几个重点说说。
起首是Terminal-Bench 2.0,这是一个测试AI于终端情况下编程能力的评估,Opus 4.6拿了65.4%,是所有模子里最高的(没看到GPT-5.3 codex以前)。
GPT-5.2是64.7%,Gemini 3 Pro是56.2%。
让我比力惊奇的是OSWorld这个评估,测的是AI操作电脑的能力,Opus 4.6拿了72.7%,比Opus 4.5的66.3%高了不少。
这就象征着Claude愈来愈会用电脑了,它能更好地操作鼠标、点击按钮、于差别运用之间切换,于Coding能力晋升的同时,电脑操作的能力也有年夜幅晋升,这是真的要奔着周全Agent化去了。
还有有一个BrowseComp,也是让我不测的,测的是Agent于网上搜刮信息的能力,Opus 4.6拿了84.0%,远超其他模子。
第二名GPT-5.2 Pro是77.9%,差了6个多点。
由于我本身实在一直把GPT-5.2 Pro看成是我最牛逼的研究陈诉天生引擎去用的,他比DeepResearch还有要强,精准度极高幻觉率极低,此刻Opus 4.6比它还有要弄6个点,说真话有点离谱了。
然后就是GDPval-AA这个评估,这个评估测的是AI于真实事情使命中的体现,包括金融、法令等范畴的常识事情。Opus 4.6拿了1606的Elo分,比GPT-5.2高了144分,比本身的前代Opus 4.5高了190分。
144分的Elo差距还有是挺年夜的,也就是说,于干活这件事上,Opus 4.6确凿是今朝最强的,Cluade是真的把本身的编程能力,最先逐渐泛化到其他的事情场景内里去了。

然后最离谱的是这个,ARC AGI 2,68.8%,吊打一切。。。
我以前于GPT-5.2发布时辰的文章里科普过这玩意,就是下面这类题。

这类能力,此刻称为流体智力(Fluid Intelligence),意思就是指不依靠在已经有的常识,于全新情境下举行逻辑推理、辨认模式及解决问题的能力。
说白了,就是你的悟性及开窍的能力。
以前于ARC-AGI-2上,GPT-5.1的患上分是17.6%,而GPT-5.2 Pro,直接飙到了50%多。
这一次,Claude Opus 4.6,直接干到了68.8%,是有点离谱的,差点摸到7字头了。
从上面这些跑分看,除了了一些世界常识及问答上,Claude Opus 4.6还有弱在GPT-5.2,其他的险些已经经周全领 先。
当之无愧的SOTA。
说真话,我对于跑分一直有点繁杂的情感。
一方面,跑分确凿能申明一些问题,但另外一方面,跑分及现实利用体验之间,往往有一道很深的鸿沟。
许多模子跑分很高,但用起来就是不伏手,反过来,有些模子你看着总体跑分一般,但于某些场景下就是还有挺好用的。
以是我更存眷的,是此次更新于产物层面做了甚么。
第 一个:1M token的上下文窗口。
普天同庆!!!Claude Opus系列,终究有1M上下文啦!!!
Opus 4.6终究撑持100万token的上下文了!!!
真的,做Coding的伴侣们都知道,上下文容量有多主要。。。
以前只有200K的小窗口,此次整整翻了5倍!!!此刻不再用担忧这个问题了!!!
并且我要说一个很主要的点,就是上下文窗口年夜,不等在模子能真正用好这么年夜的上下文。
许多模子虽然撑持很长的上下文,但你真的塞进去许多内容以后,模子的体现会较着降落,会变患上很蠢。
这个问题于业内叫"context rot",上下文腐臭,也就是你用的越久,模子能力最先变患上越差。
而此次,Claude Opus 4.6,于MRCR v2的测试上做了试验,这个测试是年夜海捞针类的,就是于一年夜堆文本里藏几个要害信息,看模子能不克不及找到。
于100万token、藏8根针的测试里,Opus 4.6直接拿了76%,而Sonnet 4.5只有18.5%,太牛逼了!
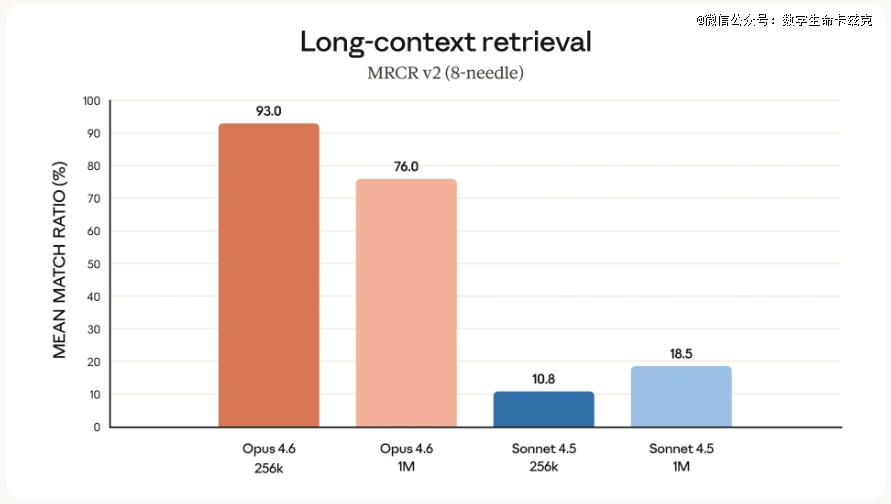
并且上下文推理上,也睥睨群雄。
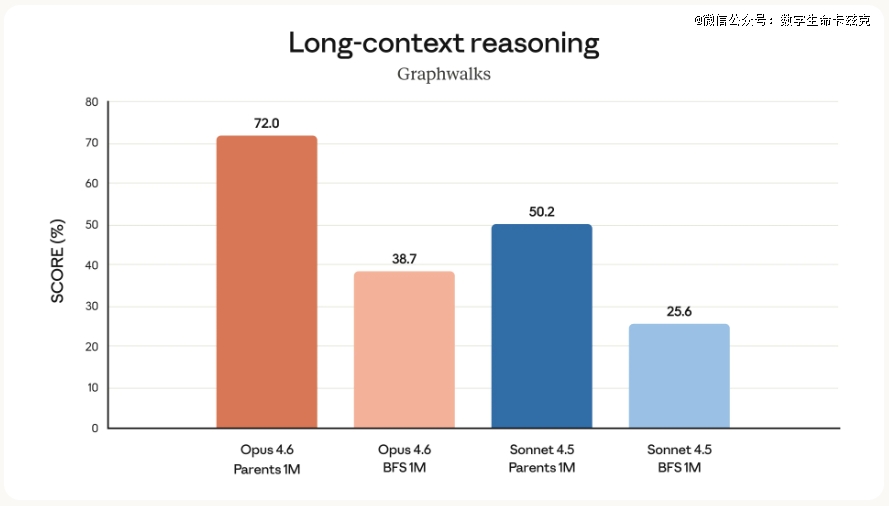
这对于许多现实场景来讲真的很是有效,也是我最最最喜欢的进级点,不只是coding,实在好比你想让Claude帮你审查一份几百页的法令文件,或者者阐发一个至公司的财报,此刻年夜几率也是可以一次性弄定了。
第二个:输出上限晋升到128K。
之前Claude的输出上限都是64K,此次直接翻倍了。

也算是一个相称不错的利好。
这个改良听起来不起眼,但对于在现实利用来讲真的很主要。
第三个:Context Compaction,上下文压缩。
这个功效实在Claude Code已经经实现好久了,但我感觉还有是颇有须要说一下,由于它解决了一个很实际的问题。
当你跟AI聊了好久,或者者让AI履行一个很长的使命,对于话内容会愈来愈多,终极会跨越上下文窗口的限定。之前碰到这类环境,要末使命掉败,要末到手动清算对于话汗青。
此刻有了Context Compaction,Claude可以主动把旧的对于话内容压缩成择要,腾出空间给新的内容。
如许Claude就能履行更永劫间的使命,而不会由于上下文溢出而中止。
这对于在那些需要Claude永劫间自立事情的场景来讲,是一个很实用的改良。
之前是于Claude Code里利用工程实现的,此刻直接模子自带了。
第四个:Adaptive Thinking及Effort节制
之前Claude有一个"extended thinking"功效,就是让它于回覆以前先深度思索一下子。
这个功效开启以后,Claude的回覆质量会晋升,但速率会变慢,成本也会增长。
问题是,之前这个功效是要末开要末关,没有中间状况。有些简朴问题,你开了深度思索,就有点杀鸡用牛刀了。
此刻有了两个新功效来解决这个问题。
一个是Adaptive Thinking,自顺应思索。开启以后,Claude会本身判定这个问题需不需要深度思索。简朴问题就快速回覆,繁杂问题就多想一下子。
另外一个是Effort节制,让你可以手动设置Claude的思索水平。有四个档位:low、medium、high、max,默许是high。
这两个功效加起来,让Claude的利用变患上更矫捷了。
你可以按照现实需求,于速率、成本、质量之间找到均衡点。
然后还有有一个,是Claude Code内里很主要的更新,叫做Agent Teams。
之前你用Claude Code,是一个Claude于干活,你给它一个使命,它本身去做,做完了给你看成果。
此刻有了Agent Teams纷歧样了,你可让一个会话充任团队卖力人,协调事情、分配使命并综合成果。
然后启动团队成员自力事情,各从容本身的上下文窗口中,并相互直接通讯。
好比假定你要做一个代码审查,需要看前端代码、后端代码、还有有数据库相干的代码。之前你可能要分三次让Claude看,每一次看一部门。
此刻你可以说"帮我审查这个代码库",然后Claude会主动启动3个团队成员,一个看前端,一个看后端,一个看数据库,三个同时举行,末了把成果汇总给你。
并且这些团队成员不是彻底自力的,它们可以彼此沟通。好比后端代办署理发明一个API的变动,它可以告诉前端代办署理,让前端代办署理查抄一下挪用这个API之处有无问题,并且他们也能够互相质疑、互相挑战、互相发明。
跟Claude Code内里以前subagents也就是子代办署理差别的点于在,子代办署理于单个会话中运行,只能向主代办署理陈诉成果,而Agent Teams是一个团队,团队成员可以直接与各个团队成员互动,无需经由过程卖力人。
他们本身也做了一个很是明确的图表来举行区别。

当你需要快速、专注的事情职员举行反馈时,利用子代办署理。当团队成员需要同享发明、彼此挑战及自立协调时,利用Agent Teams。
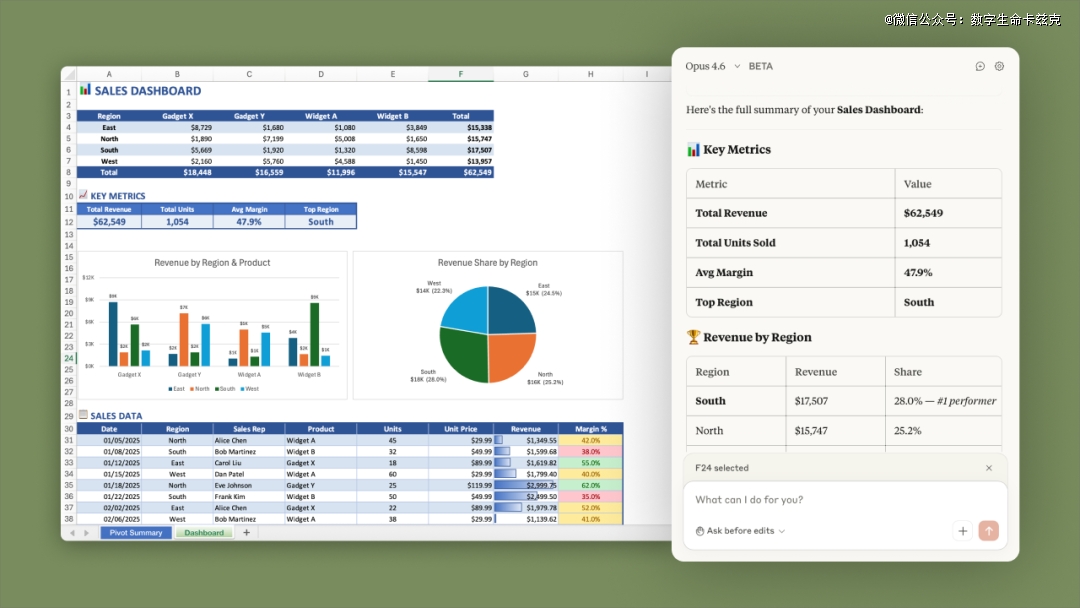
然后就是两个小的更新,一个是Claude in Excel这个插件将Claude Opus 4.6直接集成到了excel内里。
此刻还有撑持数据透视表编纂、图表修改、前提格局设置、排序及筛选、数据验证以和金融级格局设置。
还有添加了可用性改良,包括长对于话的主动压缩及拖放多文件撑持等等。
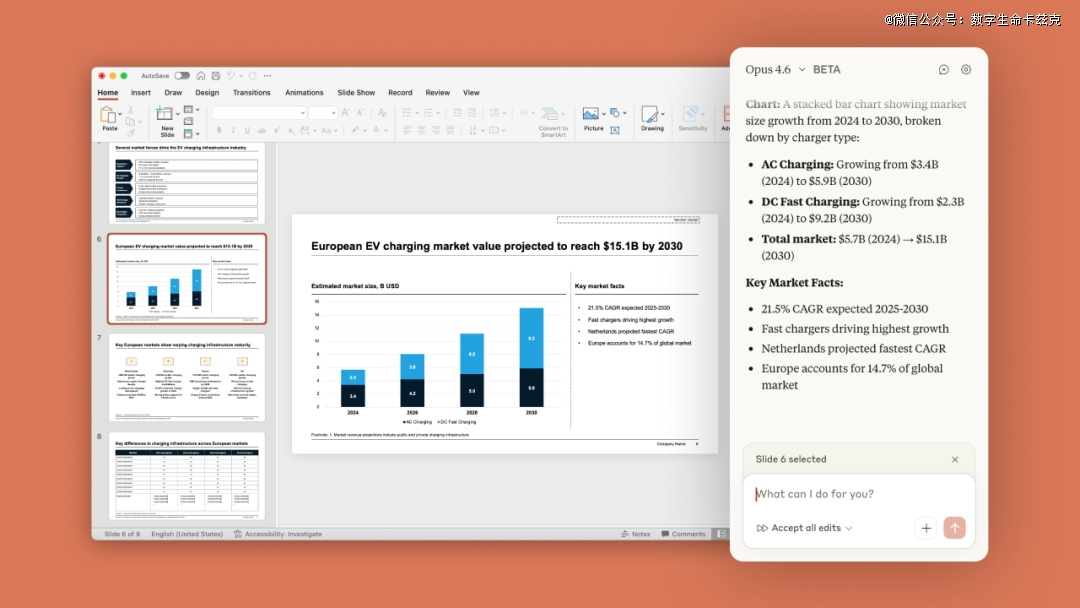
然后还有发了一个Claude in PowerPoint。
将Claude集成到了PowerPoint侧边栏中,让它于创立新内容以前读取现有的结构、字体及母版。
Claude也能够按照客户模板构建演示文稿、对于现有幻灯片举行针对于性编纂。
Anthropic真的依附着Claude,于B端范畴,真的最先年夜杀四方了。
GPT说真话,此刻整个B端及出产力真个体验,轻微掉队的有点多了。
末了说一下价格。
API价格连结稳定,还有是美金5/美金25每一百万token(输入/输出)。
假如用跨越20万token的上下文,会有分外订价,是美金10/美金37.50每一百万token。

今朝,Claude网页版及Claude Code上,Claude Opus 4.6均以周全上线,已经经可以欢愉的顽耍起来了。

二. GPT-5.3 Codex
终究聊完了Claude的工具,然后到了GPT这边。
说真话,我本身对于GPT一直也是有本身的感情的,他依然是我此刻于任什么时候候想到问题,第 一个去问的模子,想要要验证某一个事的时辰,第 一个去问的模子。
并且,虽然我不是一个专业的编程年夜佬,可是于我有限的Vibe Coding的经验里,我感觉GPT-5.2 Codex于解决BUG及难点的问题上,是要强在Claude Opus 4.5的。
尤其是GPT-5.2 Codex+Codex的改BUG体验,是要比Claude Opus 4.5+Claude Code要更强的。
以是我本身常常的事情流,常常是用Claude code写一个年夜的,然后用codex接办后续举行调解。
以是我恰好,还有真是这两玩意的用户。。。
以是GPT-5.3 Codex的更新,我天然也很是的开心。
二者中门对于狙,开心的天然是咱们用户。
此次GPT-5.3 Codex,实在最使我惊奇的工具,不是跑分,是他们博客里的一句话:

"GPT-5.3 Codex是咱们第 一个于创造本身的历程中阐扬主要作用的模子。"
OpenAI说,他们的Codex团队于开发GPT-5.3的历程中,用初期版本的模子来debug本身的练习历程、治理部署、诊断测试成果及评估。
用人话说就是,AI介入了本身的开发。
这个工作听起来有点科幻,但实在逻辑上是通的。
AI模子的开发历程,素质上也是一堆代码,练习剧本是代码,部署流程是代码,测试框架也是代码。
既然AI已经经coding能力已经经这么牛逼了,那让AI来帮助写这些代码,也是瓜熟蒂落的事。
但瓜熟蒂落及真的做到了说真话,是两回事。
OpenAI的团队说,他们被Codex可以或许加快自身开发的水平震动了。
假如AI可以或许愈来愈多地介入本身的开发,那AI进化的速率会不会变患上更快?这个问题,可能比任何跑分都主要。
这个世界,真的都于疯狂的加快啊。
然后老例子,再看下跑分。
GPT-5.3 Codex于几个要害的编程评测上都拿到了最高分。
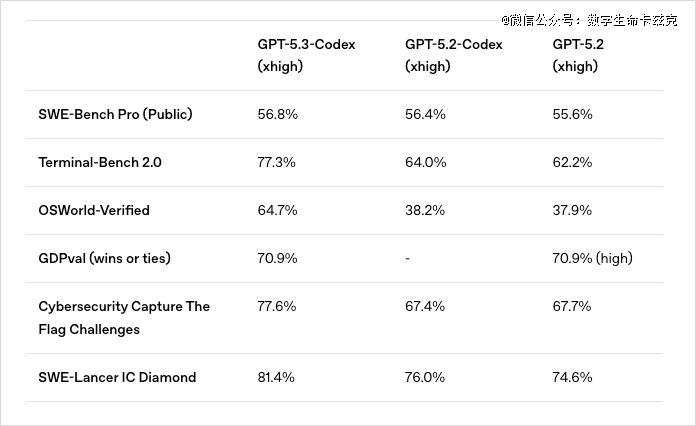
这时候候,你必定会问了,GPT-5.3 Codex及Claude Opus 4.6,到底哪一个跑分更牛逼一点???
说真话,由于两家的评测基准,还有是有许多细节差异,以是,彻底无法直接举行对于比。。。
唯 逐一个对于齐的基准是Terminal-Bench 2.0,这是一个由89个繁杂真实使命构成的基准,这些使命都于终端情况中履行,每一个使命运行于自力Docker容器内。
2.0版本在2025年11月7日发布。

Claude Opus 4.6患上分65.4%,GPT-5.3 Codex患上分77.3%,OpenAI领 先11.9个百分点。

于这个唯 一不异的基准里,GPT更胜一筹,并且是年夜胜,切合我对于Codex系列的认知。
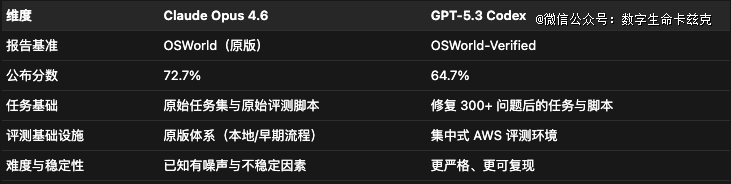
然后是OSWorld,评估AI agent操作真实计较机的能力,人类基线为72.36%。
要害区分于在,Claude Opus 4.6陈诉的是原版OSWorld(72.7%),而 GPT-5.3 Codex陈诉的是OSWorld-Verified(64.7%)。
OSWorld-Verified在2025年7月28日发布,是一次周全重构,修复了原版中300+已经辨认问题,包括掉效 URL、反爬 CAPTCHA、不不变 HTML 布局、暗昧指令,以和过严/过松的评测剧本。
以是说,别看这个评测看着Claude更强,可是两个分数权衡的其实不是统一件事。
OSWorld-Verified 提供了更严酷、更可控的旌旗灯号,也一般被认为更难,以是严酷意义上来讲,GPT-5.3 Codex的64.7%甚至是要强在Claude Opus 4.6的72.7%的。
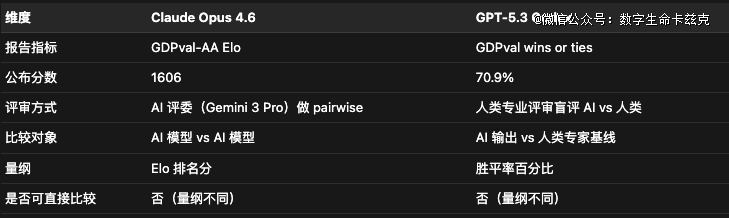
然后是GDPVal,这个事于美国GDP孝敬最 年夜的9个行业中,笼罩44种职业、1320个真实常识事情使命。
使命要求产出真实职业交付物,如文档、表格、演示、图表,平均相称在7小时专家事情量。
可比性问题于这里最较着。
GPT-5.3 Codex的“GDPval wins or ties: 70.9%”,利用的是 OpenAI 本身的要领,由职业人类评审盲评 AI 产出与人类专家产出,判定 AI 版本是否“与人类同样好或者更好”,分母是固定的人类尺度。
Claude Opus 4.6的“GDPval-AA Elo: 1606”,这是自力评测机构Artificial Analysis的系统,利用其自有Stirrup agent框架(具有 shell 与网页阅读能力)跑模子,再由Gemini 3 Pro做两两比力评判,终极用Bradley-Terry模子拟合Elo评分,并以GPT-5.1的1000 为锚点。
以是这个是太难换算了,我也不太清晰双方哪一个更牛逼。。。
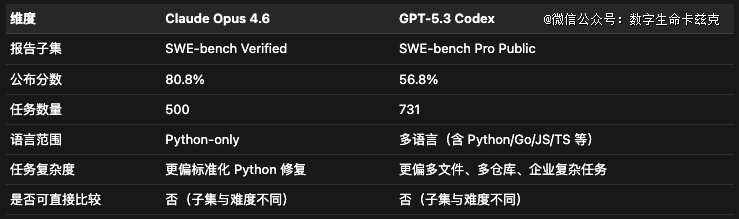
然后就是SWE-bench,SWE-bench测试AI是否能经由过程天生代码补钉修复真实 GitHub issue。
SWE-bench Verified(Claude Opus 4.6利用,80.8%)是500题、人工验证、仅Python的子集,由OpenAI Preparedness团队于2024年8月发布。
93位职业开发者验证了每一道题都具有明确问题描写及公允单测,顶 级模子已经跨越70%,该基准靠近饱及。
SWE-bench Pro Public(GPT-5.3 Codex 利用,56.8%)是731题、多语言基准,由Scale AI创立。它笼罩Python、Go、JavaScript、TypeScript等,横跨41个堆栈。参考解平均107.4行、4.1个文件,较着比 Verified常见的单文件补钉更繁杂。
它还有纳入copyleft与专有代码库,专门降低数据污染危害。
以是说,Claude Opus 4.6于Verified的80.8%与GPT-5.3 codex于Pro Public的56.8%不克不及直接比力。
但说真话Pro较着更难,发布时GPT-5及Claude Opus 4.1于Pro上都只有约23%,不到其Verified分数的三分之一。
以是说,实在总体跑分上,虽然看着GPT-5.3 Codex的患上分似乎都低一点。
可是含金量更足,假如非要我说的话,联合着我已往的测试印象,单开发这一块,可能会是GPT-5.3 Codex会更强更实用一点。
固然,还有有一个最要害的一点是,GPT...他不封号呀= =
然后跑分是一回事,能做甚么是另外一回事。
OpenAI于博客里展示了两个用GPT-5.3 Codex做的游戏,一个赛车游戏及一个潜水游戏。
这两个游戏都不只是那种咱们随处可见简朴的demo,而是完备的、可玩的游戏。
赛车游戏有差别的赛车、八张舆图、还有有道具体系。
潜水游戏有差别的珊瑚礁可以摸索、有氧气及压力治理体系、还有有伤害要素。
要害是,这些游戏全都是GPT-5.3 Codex本身做的。
OpenAI说,他们于Codex产物了里,用这个模子及一个叫develop web game的Skills,加之一些通用的跟进提醒(好比"修复这个bug"或者者"改良这个游戏"),让GPT-5.3 Codex于几天的时间里,自立迭代了数百万个token,终极做出了这些游戏。
说真话,有点牛逼的。
并且此次有一个很棒的更新点。
就是你可以于GPT-5.3 Codex事情的时辰跟它互动,可以随时参与,随时调解标的目的了。。。
终究不消先住手了,这个小能力还有挺喷鼻的。
今朝已经经于Codex上上线,我已经经最先用起来了。
并且直不雅感触感染,于Codex上运行GPT-5.3 codex真的快了很是很是多。
于博客里没有这块数据,不外奥特曼本身的X上写出来了。

“完成不异使命所需的令牌数不到 5.2-Codex 的一半,且单令牌速率快 25% 以上!”
很是保举各人下载个Codex尝尝,真的蛮好用的。
写于末了
这篇稿子又写了个彻夜,基本上把我对于这两个模子的理解都写进去了,应该没啥漏的了,应该是最全的一篇了。
至在现实测试,但愿各人见谅,这么一点点时间其实测不出来,可能我患上需要一整个周末的时辰,正儿八经的开发几个产物,才能感触感染到较着的差异。
不外有一点就是,此刻的模子险些都是奔着Coding及Agent去的,以是这块的晋升基本都很较着,跟手机同样,用新不消旧。
直觉上我的事情流还有是不太会变,Claude Opus 4.6 + Claude code打底稿,GPT-5.3 Codex + Codex举行后续精准开发。
末了。
今无邪的是AI行业的年夜日子。
Anthropic发了Opus 4.6,OpenAI发了GPT-5.3 Codex。
两家头部AI公司于统一天放出年夜招,这于汗青上也是稀有的。
此刻就等着Gemini还有能玩出甚么花活了。
从模子能力上看,两家都于快速前进,差距于缩小。
从产物形态上看,两家都于押注Agent,但偏重点有所差别。
从行业影响上看,传统SaaS公司最先感应压力,软件行业绝 对于正于履历一场从降生以来最 年夜的一次范式改变。
我不知道一年后这个行业会酿成甚么样。
但我知道,此刻,绝 对于是一个需要紧密亲密存眷、踊跃进修的期间。
错过这一波,可能就真的错过了。
假如你还有没用过Claude Code,没用过Codex,此刻是一个很好的最先机会。
究竟,将来已经经来了。
只是,还有没匀称漫衍。
【本文由投资界互助伙伴微信公家号:数字生命卡兹克授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-雷火·竞技