


首页财产阐发评论ai正文 OpenAI及Anthropic深夜同发年夜招 2026年Claude Opus 4.6及GPT-5.3 Codex相隔不到一小时前后发布,两者于多方面揭示强盛能力,这次竞争鞭策AI立异,标记其进入新阶段。 2026-02-06 09:43 ·字母榜苗正 苗正 AI投资人解读· Claude Opus 4.6能主动调解思索深度,代码能力强,长文本处置惩罚精彩,于金融范畴运用领先,产物配套更新多,安全评估周全。GPT-5.3 Codex能边干活边沟通,可自我练习,于多基准测试中创纪录,统筹用户体验,运用广泛。 · 行业竞争激烈,产物发布节拍快,需连续立异;安全方面虽有评估及防护,但仍可能存于危害。 总结:两款产物各有上风,代表AI成长新阶段。投资时需存眷竞争态势与安全危害,联合其技能迭代及运用拓展能力综合评估。内容由AI天生,仅供参考
2026年的这一天注定会被写入AI成长史。
Claude Opus 4.6及GPT-5.3 Codex于相隔不到一个小时的时间里前后发布。
两家公司好像都憋着一口吻,要于统一个时间节点上交出本身的答卷。
“撞车”的暗地里,是一场关在本钱、技能及市场话语权的较劲。
就于两周前,英伟达方才公布向Anthropic投资100亿美元,这笔钱让Anthropic的估值飙升到3500亿美元。
动静传出后不到72小时,英伟达回身又向OpenAI注资200亿美元。
黄仁勋的算盘打患上很清晰:双方都押注,谁赢都不亏。
但对于Anthropic及OpenAI来讲,这不只是拿到钱那末简朴。
两家公司都规划于2026年下半年到2027年摆布启动上市步伐,此刻恰是证实本身技能实力、争取市场订价权的要害时刻。
投资人要看的不是PPT上的承诺,而是能拿脱手的产物。
谁的模子更强,谁于现实运用中更有说服力,谁就能于IPO时要到更高的价格,拿到更多的筹马。
一山容不患上二虎,Anthropic及OpenAI必需患上让对于方大白,谁才是老年夜。
是以,这类产物节拍不是偶合,而是卡好了表的对于轰。
两家公司都清晰,于这个时间点上,每一一次产物发布都是一次融资路演,每个技能冲破城市直接影响投资人的判定及市场的预期。
不外从产物自己来看,两家公司确凿都拿出了真本领。
01
Claude Opus 4.6
Anthropic此次对于 Claude Opus 系列的进级,焦点放于了“更智慧地思索”这件事上。
Opus 4.6最显著的变化是它学会了“adaptive thinking”,模子会按照使命的繁杂水平主动调解思索深度。于坚苦问题上花更多时间思索,而于简朴使命上快速经由过程。
于代码能力方面,Opus 4.6于Terminal-Bench 2.0这个评测中拿到了最高分。
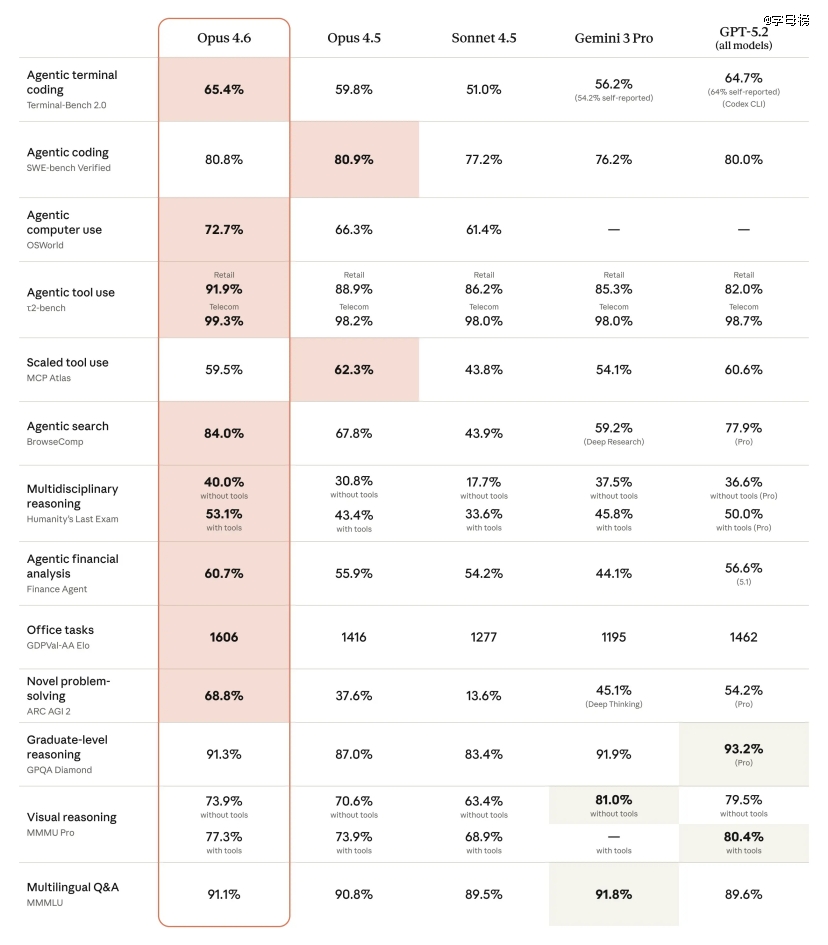
这个测试专门考查AI于终端情况下的操作能力。模子需要知道何时该用哪一个号令,怎样组合差别的东西,以和怎么从过错信息里找到问题地点。
这就像是考查一个步伐员会不会纯熟利用各类开发东西。不只是写代码,还有要会调试、会部署、会看日记找bug。
更主要的是,Opus 4.6是Anthropic第 一个提供100万token上下文窗口的Opus级别模子。这个数字象征着模子可以一次性处置惩罚相称在两本中等厚度小说的文本量。
于长文本处置惩罚的测试中,Opus 4.6于MRCR v2的8-needle 1M 变体上患上分76%,而上一代的Sonnet 4.5只有 18.5%。
简朴一点来理解,就是给模子一年夜堆文档,然后问它一个需要综合多处信息才能回覆的问题。
之前的模子看着看着就“忘了”前面的内容,或者者找不到要害信息。Opus 4.6能于海量文本里正确定位需要的信息,并且不会由于文档过长就体现降落。
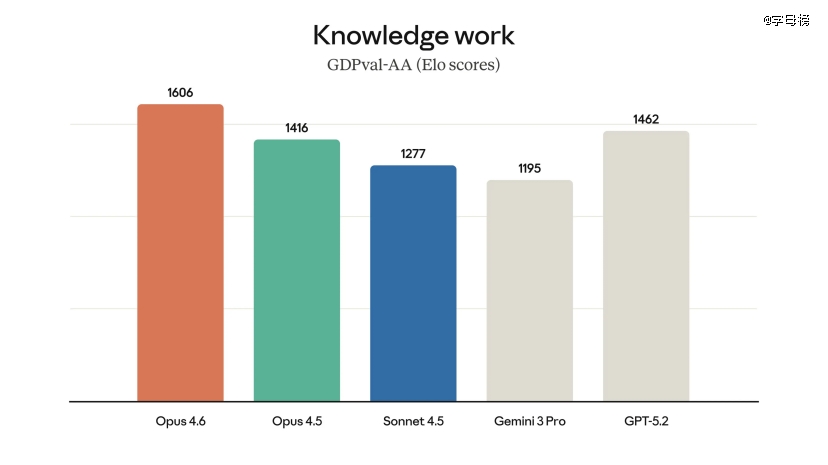
于常识事情能力的评测GDPval-AA 上,Opus 4.6比OpenAI的GPT-5.2超出跨越约144Elo分,比本身的前代Opus 4.5超出跨越190分。这个测试涵盖了金融、法令等范畴的现实事情使命,好比建造财政阐发陈诉、草拟法令文件、做市场调研等。
Anthropic还有于产物层面做了不少配套更新。
Claude Code此刻撑持“agent teams”功效,可以同时启动多个AI代办署理,让它们各自大责差别的子使命,然后主动协调事情。
对于在那些年夜型的代码库,这个功效尤其有效,可以把事情拆分给差别的代办署理并行处置惩罚。
于办公软件集成方面,Anthropic推出了Claude in PowerPoint的研究预览版,并年夜幅进级了Claude in Excel。
此刻Claude可以直接于Excel里处置惩罚更繁杂的使命,撑持数据透视表编纂、图表修改、前提格局化等功效。于 PowerPoint 里,Claude 能读懂现有的版式、字体及母版设计,然后根据这个气势派头创立新的幻灯片。
就是让AI真正进入你一样平常事情的东西里。不消往返复制粘贴,直接于Excel或者PowerPoint的侧边栏跟Claude对于话,它就能帮你改表格、做图表、天生演示文稿。
并且它会进修你的气势派头,做出来的工具不会显患上扞格难入。
于API层面,Anthropic引入了“effort”参数,提供低、中、高、最高四个档位。
开发者可以按照使命的繁杂度选择适合的档位,于成本、速率及质量之间找均衡。还有有“context compaction”功效,当对于话靠近上下文窗口限定时,会主动总结并替代较早的内容,让永劫间运行的使命不会由于凌驾限定而中止。
可以理解为给开发者更多的节制权。
简朴使命用低档位,省钱又快;繁杂使命用高等位,包管质量。对于话过长了体系会主动压缩前面的内容,如许就能一直聊下去。
于安全性方面,Anthropic此次做了他们有史以来最周全的安全评估。
Opus 4.6于主动化举动审计中显示出较低的不妥举动率,包括棍骗、谄谀奉承、鼓动勉励用户贪图及共同滥用等。
因为 Opus 4.6于收集安全方面的能力有显著晋升,Anthropic专门开发了六个新的收集安全“探针”来检测潜于的滥用举动。
同时,他们也于用这个模子帮忙开源软件查找及修补缝隙,但愿让防备方也能用上AI的气力。
02
Advancing Finance:
金融范畴的深度运用
Anthropic专门发布了一篇文章,具体先容Claude Opus 4.6于金融范畴的运用。
于金融事情中,专业人士需要AI做三件事:研究、阐发及创立交付物。Opus 4.6于这三个维度上都到达了业内领 先程度。
于研究能力上,Opus 4.6于BrowseComp及DeepSearchQA两个基准测试中都有晋升。
这两个测试考查的是模子从年夜量非布局化数据中提取特定信息的能力。
对于金融阐发师来讲,这象征着可以把一堆公司财报、行业陈诉、新闻文章扔给AI,然后问一个很详细的问题,AI能给出针对于性的谜底,而不是泛泛的总结。
你丢给它一份财报,之前问AI“这家公司的盈利能力怎样”,它可能给你的是一年夜段话,然后再把财报内容复述一遍。
此刻它能直接告诉你要害指标是甚么,跟行业平均程度比怎么样,有哪些危害因素。
于阐发能力上,Opus 4.6于 Finance Agent这个外部基准测试中到达60.7%的正确率,比Opus 4.5晋升了5.47个百分点。
于税务评估TaxEval 上,Opus 4.6也到达了76%的业内最高程度。
Anthropic用一个贸易尽职查询拜访使命做了对于比,他们让Claude Opus 4.6去评估一个潜于的收购方针。这类事情凡是需要一个资深阐发师花两到三周时间才能完成。
可是Opus 4.6的初次输出于布局、内容及格局上都比Opus4.5更靠近可以直接利用的尺度。
也就是说,此刻做出来的工具你小改一下就能用。这对于在需要快速产出陈诉、演示文稿的金融从业者来讲,效率晋升是实其实于的。
Anthropic的内部“真实世界金融”评估涵盖了约50个投资及财政阐发用例,包括电子表格、幻灯片及文档的天生与审视。
这些是投资银行、私募股权、公然市场投资及企业财政范畴阐发师的常见使命。Opus 4.6比几个月前的Sonnet 4.5晋升了跨越23个百分点。
共同Cowork这个新功效,金融团队可以同时启动多个阐发使命。Cowork让Claude可以拜候你指定的当地文件夹,直接于内里读取、编纂及创立文件。
对于金融团队来讲,这象征着可以一次性安插几个阐发使命,同时监视 Claude 创立每一个交付物的历程,确保切合本身的尺度。
03
GPT-5.3 Codex:
本身练习本身的模子
于Claude Opus 4.6发布的几十分钟后,奥特曼忽然发了一条X,公布GPT-5.3 Codex。
我于这里也是代表字母AI,给奥特曼及阿莫迪一点体面,给他们别离点了喜欢及转发。
GPT-5.3 Codex最牛之处于在,它能像真人同事同样干活,并且可以边干活边跟你磋商。
之前的AI是“你说一句我做一句”,GPT-5.3 Codex是“有问题随时问你”。
你给它一个繁杂使命,它能本身揣摩几个小时甚至几天,半途还有会自动跟你报告请示进度、问你定见,你随时可以插话调解标的目的。
成心思的是,OpenAI用GPT-5.3 Codex的初期版原来帮助开发后续版本。也就是说,让AI帮着调试AI的练习历程、修bug、优化体系,OpenAI团队说这闪开发速率快患上惊人。
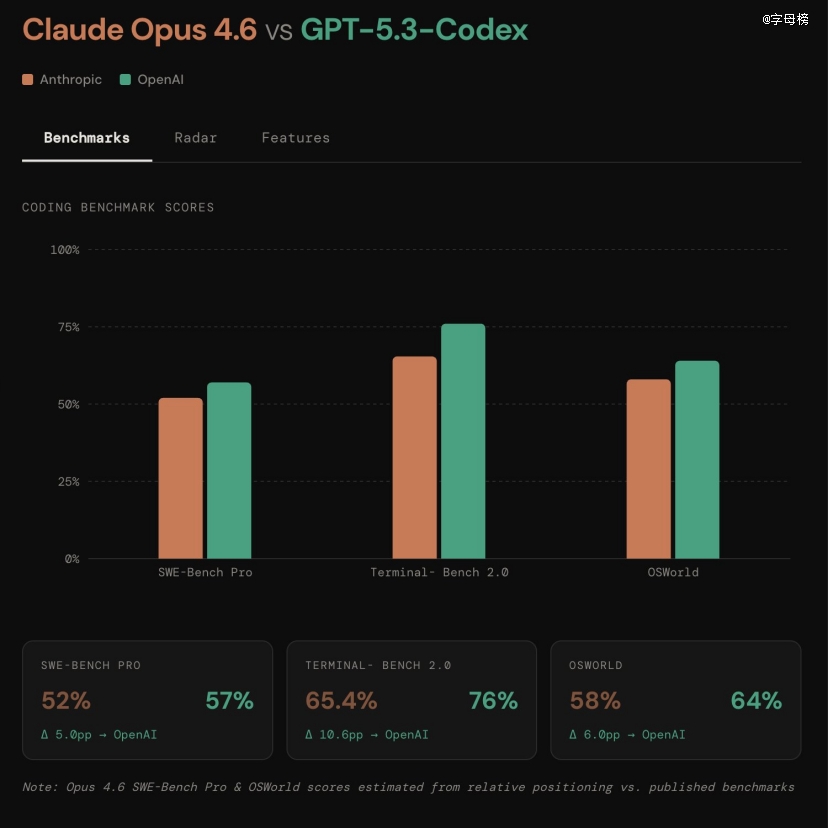
GPT-5.3 Codex于多个基准测试中创造了新的行业纪录。于SWE-Bench Pro上,它到达了56.8%的正确率,这是一个严酷的真实世界软件工程评估。
与只测试Python的SWE-bench Verified差别,SWE-Bench Pro涵盖四种编程语言,更抗污染、更具挑战性、更多样化,也更切近行业现实。
于Terminal-Bench 2.0上,GPT-5.3 Codex到达77.3%,远超以前的64%。
这个测试权衡的是代码代办署理需要的终端技术,也就是于号令行情况下完成各类操作的能力。值患上留意的是,GPT-5.3 Codex用的token数目比以前任何模子都少,这象征着用户可以用一样的成本做更多工作。
于 OSWorld-Verified 这个测试中,GPT-5.3 Codex患上分 64.7%,而GPT-5.2-Codex只有38.2%。
这是一个代办署理计较机利用基准测试,AI需要于可视化的桌面计较机情况中完成出产力使命。人类于这个测试中的患上分约为72%,GPT-5.3 Codex已经经靠近人类程度。
于网页开发方面,OpenAI展示了一个对于比案例:让GPT-5.3 Codex及 GPT-5.2-Codex别离创立一个 SaaS 产物的落地页。
GPT-5.3 Codex主动把年度套餐显示为扣头后的月度价格,让优惠看起来更清楚、更成心图,而不是简朴地把年度总价乘出来。
它还有做了一个主动切换的用户评价轮播,包罗三条差别的用户评价,而不是只有一条,让整个页面觉得更完备、更靠近可以上线的状况。
简朴来讲,就是它会思量用户体验及营销效果。不是机械地实现功效,而是会想“怎么做更好”。这类对于细节的掌握及对于终极效果的理解,让它做出来的工具更靠近专业程度。
GPT-5.3 Codex的能力不仅限在编码。
它撑持软件生命周期中的所有事情,好比调试、部署、监控、编写产物需求文档、编纂案牍、用户研究、测试、指标阐发等等。
于GDPval测试中,GPT-5.3 Codex的体现与GPT-5.2持平,到达70.9%的胜率或者平手率。这个测试权衡的是模子于 44 个职业的明确常识事情使命上的体现,包括建造演示文稿、电子表格及其他事情产物。
一个有趣的细节是,两家公司都夸大了“本身用本身的产物”。Anthropic 说“咱们用 Claude 来构建 Claude”, OpenAI说“GPT-5.3 Codex于本身的开发中阐扬了要害作用”。
这实在是最 好的告白,假如本身的工程师都不肯意用,怎么能期望他人用?
并且从技能演进的角度看,两个模子都代表了 AI 从“回覆问题”到“完成事情”的改变。
它们再也不满意在天生一段文字或者一段代码,而是要可以或许履行完备的事情流程,产出可以直接利用的交付物。这类改变对于 AI 的要求高患上多:不仅要懂技能,还有要懂营业;不仅要能做,还有要做患上好;不仅要快,还有要稳。
值患上留意的是,两家公司都没有逃避 AI 能力晋升带来的危害。Anthropic 做了“有史以来最周全的安全评估”, OpenAI 部署了“最周全的收集安全防护办法”。
从用户角度看,两家公司的竞争是功德。差别的需求可以找到差别的解决方案,差别的事情方式可以选择差别的东西。更主要的是,竞争会鞭策两边继承立异,让AI能力的界限不停扩大。
并且这两个产物的发布也标记着AI进入了一个新阶段。再也不是“能不克不及做”的问题,而是“怎么做患上更好”的问题。
【本文由投资界互助伙伴字母榜授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-雷火·竞技