


首页财产阐发评论芯片半导体正文 芯片,最新瞻望 今日斯坦福年夜学发布《2026年新兴技能瞻望》,先容10项前沿技能,半导体是要害一环。最近几年芯片能耗降落放缓、成本上升,行业面对挑战与机缘。 2026-02-03 09:45 ·微信公家号:半导体行业不雅察Stanford Stanford AI投资人解读· 半导体是现代糊口要害组件,运用广泛。芯片制造技能前进使处置惩罚更节能,但存储硬件能耗降落放缓、成本上升。台积电是全世界最年夜芯片代工企业,2024年占超60%半导体代工市场份额。人工智能等鞭策行业成长,新技能将晋升机能、带宽及能效。 · 摩尔定律上风削弱致芯片制造成本上升;行业集中度高、美国产能低下使全世界芯片供给链懦弱;热治理、存储技能立异面对挑战。 总结:半导体行业远景广漠但挑战并存,投资需存眷技能进展、市场格式和成本变化,综合评估潜于危害与收益。内容由AI天生,仅供参考
今日,斯坦福年夜学发布斯坦福年夜学《 2026年新兴技能瞻望》。于228页的陈诉中,他们具体先容了10项前沿技能,半导体就是此中的主要一环。本文中,咱们摘译了相干部门,以飨读者。
半导体,凡是以微芯片的情势存于,是一样平常糊口中各类物理装备的要害组件,从智能手机及烤面包机到汽车及割草机,无所不包。芯片节制着现代修建中的供温和制冷体系、电梯及火警报警器。交通讯号灯也由芯片节制。于农场,拖拉机及浇灌体系也由芯片节制。现代军 队的兵器、导航装备及战斗机的座舱生命维持体系都离不开芯片。如许的例子不乏其人——于现代糊口的各个方面,芯片都至关主要。
年夜大都芯片都介入信息处置惩罚。差别类型的芯片各司其职,履行差别的使命。有些是处置惩罚器芯片,卖力吸收数据、对于数据举行计较并输出计较成果。存储芯片用在存储信息,并与处置惩罚器共同利用。还有有一些芯片充任数字计较与物理世界之间的接口。于所有这些环境下,都需要必然的能量来暗示芯片内部的每一一名信息。芯片的神奇的地方于在,于芯片内部暗示信息所需的能量比于芯片外部(例如,毗连芯片的导线)暗示信息所需的能量要少几个数目级。这象征着,于多芯片体系中,芯片间数据传输所需的能量及芯片空间弘远在芯片内部数据;这也是鞭策于单个芯片上集成更多功效的重要动力之一。
跟着芯片制造技能的前进,暗示给定信息位所需的能量及芯片空间愈来愈少;是以,处置惩罚这些信息位变患上越发节能。恰是这类征象使患上半导体行业可以或许跟着时间的推移于芯片上集成更多的处置惩罚能力——它使设计职员可以或许制造出履行更繁杂处置惩罚的芯片(拜见图 9.1)。然而,设计成本也跟着芯片繁杂性的增长而增长。
然而,最近几年来,芯片上存储信息的硬件的能耗降落速率放缓,单元面积的制造成本却有所上升。这象征着,芯片尺寸缩小带来的成本及能耗上风险些已经经消散。是以,研究职员一直于摸索其他要领来改良计较机技能,并解决设计成本昂扬的问题。
因为履行差别芯片功效的最 佳技能自己就差别,是以体系仍旧需要利用差别的芯片来实现这些功效。寻觅新的要领来治理芯片内部及芯片之间信息传输的低效性,以和解决昂扬的设计成本问题,是半导体研究的焦点重点。进一步的改良将表现于设计、质料及集成要领的立异上。
就本陈诉而言,芯片的两个方面至关主要。它们必需颠末设计及制造(即出产),并且每一种功效都需要差别的技术。芯片设计重要是一项智力使命,需要可以或许创立及测试包罗数十亿个组件的体系的东西及团队。制造重要是一项体力劳动,需要年夜型工场或者晶圆厂,这些工场可以或许以数百万甚至数十亿的速率出产芯片——并且从零最先制作可能需要数十亿美元,耗时数年。
芯片制造触及浩繁繁杂工艺流程。每一一项工艺流程都需要年夜量的专业常识才能把握及操作,而所有工艺流程的整合则需要更深切的专业常识。是以,现代芯片制造工场的运营需要年夜量受过工程培训的职员。
制造历程也需要年夜量的工艺工程,以不停改良工艺技能并到达严酷的制造尺度。例如,芯片制造所用的“干净室”所需的空气比病院手术室的空气无颗粒物含量超出跨越一千倍。
因为芯片设计及芯片制造的性子大相径庭,只有少数公司(例如英特尔)同时从事这两项营业。然而,英特尔今朝面对困境,一些技能阐发师及英特尔前高管认为,英特尔应该将其设计及制造部分拆分。很多公司专注在设计,包括高通、博通、苹果及英伟达。这种公司被称为“无晶圆厂”(fabless),由于它们卖力设计事情,并将制造外包给其他公司——这类计谋基在如许的理论:前者比后者利润率更高。
如今,外包营业的“others”凡是指的是一家公司:台积电(TSMC),迄今为止全世界最 年夜的芯片代工企业。2024年,台积电节制着全世界跨越60%的半导体代工市场份额及90%的进步前辈芯片市场份额。韩国三星位居第二,约占全世界芯片市场份额的13%。一样位在中国台湾的联华电子(UMC)排名第三,市场份额约为6%。
比拟之下,美国的芯片制造能力已经年夜幅下滑。1990年,美国芯片制造厂占全世界产量的37%,但到2021年,这一比例已经降至仅12%。行业集中度高、美国产能低劣等因素,鞭策美国在2022年经由过程《创造有益在半导体出产的激励办法法案》(CHIPS法案),但全世界芯片供给链于可预感的将来仍将连结懦弱。
半导体系体例造的实力影响远不止信息技能。它也是地球上最周详的制造要领,如今正鞭策着从神经科学及合成生物学到能源及照明等诸多范畴的立异。虽然此中很多运用其实不需要最 进步前辈的加工技能,但它们确凿需要半导体系体例造及制造方面的专业常识。
要害进展
摩尔定律:已往与将来
半个多世纪以来,信息技能的成长一直遭到芯片制造工艺改良的鞭策。1965年,英特尔结合开创人戈登·摩尔不雅察到,晶体管的制造成本随时间呈指数级降落——这一不雅察成果厥后被称为摩尔定律。它并不是物理定律,而是对于芯片制造工艺改良所能带来的经济价值最 优速度的描写。
虽然摩尔定律凡是被表述为芯片上的晶体管数目每一隔几年翻一番,但从汗青上看,鞭策这类范围扩张的真正缘故原由是芯片的制造成本于很年夜水平上与芯片上的元件数目无关。这象征着,每一隔几年,尺寸及成本年夜致不异的芯片上的晶体管数目就会翻一番。
摩尔定律(即芯片上晶体管数目的指数级增加)象征着,每一年人们都能以更低的成本制造出与去年不异的装备,或者者以不异的成本制造出更强盛的体系。这类增加云云不变,以至在人们遍及认为计较成本会跟着时间的推移而不停降落。这类预期云云遍及,以至在于险些所有事情范畴,人们都于开发更繁杂的算法以取患上更好的成果,同时又期望摩尔定律可以或许帮忙他们防止因算法繁杂性增长而带来的后果。
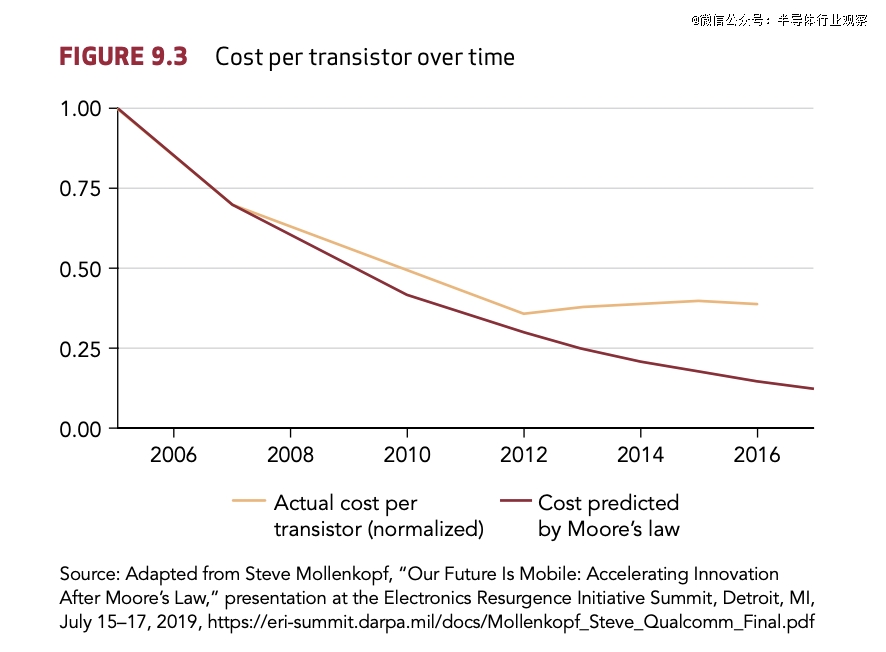
但将来不会与已往不异。跟着芯片繁杂性的增长,与摩尔定律相干的传统上风正于削弱,致使芯片制造成本上升。如图 9.3 所示,从 2004 年到 2012 年,每一个晶体管的现实芯片成本(橙色实线)与摩尔定律猜测的成本(红色实线)基本吻合。然而,每一个晶体管的现实成本于 2012 年摆布最先趋在平稳,今后便未能跟上摩尔定律的猜测。
从汗青上看,技能的前进来自在晶体管及毗连它们的导线尺寸的缩小,而技能的名称则来历在设计中的最小特性(例如,130 纳米 [nm] 芯片是指最小特性的宽度为 130 nm 的芯片)。
然而,十多年前,提高电路密度(以每一平方厘米的电路数目权衡)变患上愈来愈坚苦。人们不能不寻觅其他要领,例如使用晶体管的垂直尺寸来减小其面积。
使用垂直尺寸以和其他更繁杂的加工技能(例如利用新质料)使患上电路密度患上以连续提高。但只管这个间隔再也不代表任何物理意义,技能营销职员仍旧继承利用不停缩小的间隔来描写新一代更密集的电路。换句话说,这个名称酿成了一种营销手腕(或者者更婉转地说,是一种代际技能标签),只管它听起来仍旧像是指间隔。
当标签具备现实的物理意义,例如唆使某个特性的尺寸时,该数字(例如 130 纳米)可用在揣度芯片机能,例如每一次计较的现实成本或者计较所需的能量。但一旦它成为营销术语,标签与芯片机能之间的接洽就断开了。
于此配景下,已往一年半导体行业取患了显著的前进,同时也面对着诸多挑战。例如,人工智能 (AI) 及呆板进修 (ML) 运用对于计较能力的需求不停增加,致使进步前辈图形处置惩罚器 (GPU) 的开发及需求激增。这给出产及能源资源都带来了压力。
传统处置惩罚器并不是现代 AI 算法所需的高强度计较使命的最 佳解决方案。是以,人们于开发 GPU 及其他专为 AI 事情负载设计的专用场理器方面投入了年夜量资金。这类改变正于重塑半导体行业,凸显了对于高机能、高能效计较解决方案的需求。
经由过程尺寸缩放及进步前辈封装技能,密度显著提高,使患上进步前辈的GPU体系可以或许于狭窄的空间内集成海量计较资源,从而晋升机能。(进步前辈封装技能是指将多个半导体芯片或者晶粒的电路集成到单个紧凑的电子封装中,例如2.5D集成。)英伟达的GB200 NVL72体系就是一个例子。然而,业界未能像已往那样迅速降低功耗及制造成本,是以这些呆板价格极为昂贵且功耗极高。它们的功耗是几年前体系的十倍。此外,还有需要立异技能来为体系供电及散热。对于高机能的激增需求凸显了寻觅立异解决方案的主要性,以便以最节能、最简洁(别离降低功耗及成本)的方式满意计较需求。
应答这一挑战需要专用硬件,这类硬件必需可以或许极为高效地计较现今人工智能运用所需的成果。这是今朝已经知唯 一可以或许晋升单元成本及单元功耗计较机能的要领。如今,所有效在人工智能运用的计较装备,包括GPU,都包罗这类专用硬件。英伟达陈诉称,其优化办法将履行计较所需的能量降低了一千倍。但即便颠末这些优化,今朝的计较体系仍旧会披发年夜量热量(每一个机架跨越100千瓦[kW])。比拟之下,美国平凡家庭整年平均用电量约为1千瓦时——并且估计将来体系的用电量还有会连续增加。
芯片组及2.5D集成
将年夜量的计较及内存集成到单片硅片上是实现最高能效的抱负选择。然而,这带来了两个问题。起首,现今一些要求极高的运用所需的计较资源跨越了单片硅片所能承载的量。其次,处置惩罚器及内存的制造工艺大相径庭,是以这两个组件没法放置于统一片硅片上。
解决这些挑战的一种方案是利用芯片组及2.5D集成。这类要领并不是将所有组件都强行集成到单片硅片上,而是将多个硅片经由过程中介层毗连起来,从而创立一个更年夜的超等芯片。
这类超等芯片使用芯片组及2.5维集成技能将处置惩罚器及内存集成于一路,并使用差别的制造工艺来优化每一个组件。芯片组——硅片的功效模块——可以以各类方式组合,使供给商可以或许按照客户需求定制体系。 2.5D 集成技能的焦点是中介层,这是一种非凡的基板,它毗连芯片组,并实现比传统电路板布线更快、更节能的通讯。经由过程答应高密度存储器、高机能计较单位及通讯芯片并排摆列,这类要领提高了带宽、机能及能效,同时削减了于单个芯片长进行彻底集成的需求。
这些超等芯片可以同时包罗存储器及处置惩罚器。与传统的单片芯片设计比拟,2.5D 集成技能带来了显著的厘革,因为晶体管地点的芯片及基板都需要制造,是以每一个晶体管的成本有所增长。只管云云,2.5D 集成技能使半导体公司可以或许创立一系列可以以各类方式组合的构建模块芯片组,从而实现前面提到的具备差别机能特性的各类产物。这类计谋使公司可以或许更好地按照特定运用范畴定制产物,并更有用地实现硅投资的盈利,终极提高产物多样性及市场相应能力。
鉴在范围经济的变化,芯片组的利用降低了总体成本,并实现了更定制化的解决方案。半导体公司AMD的做法即是这一计谋的范例。AMD将数据传输组件保留于较旧的工艺节点上,同时采用最新的工艺来晋升焦点计较资源。此外,这类模块化计谋还有有助在集成新兴技能,例如光子学(本章稍后将具体会商),从而显著提高芯片内部及芯片之间的通讯速率及带宽。
高功率密度
将计较单位及内存单位靠患上更近可以晋升体系机能。但所有此类体系城市孕育发生热量——于单个芯片上集成更多单位会增长体系运行时期需要披发的热量。
例如,于英伟达的 NVL72 体系中,它将 72 个 B200 2.5D 超等 GPU 集成到一个机架中,并利用其高机能 NVLinks 技能将所有 GPU 毗连起来,从而形成一个具备强盛计较能力及带宽的超等计较机集群。这些配置中的每一个 GPU 的机能约莫是消费级 GPU 的十倍,每一个 GPU 的功耗约为 1 千瓦。两个如许的 GPU 安装于一块功耗为 2.7 千瓦的电路板上,而这些电路板又安装于一个总功耗为 120 千瓦的机架中。四到八个如许的机架可以经由过程长间隔链路毗连于一路,
从而创立一个散热量为 0.5 到 1 兆瓦的超等集群。 (比拟之下,一栋2500平方英尺的衡宇可能需要一台孕育发生约30千瓦热量的暖气炉。)
是以,热治理显患上尤为要害。已往,计较机装备的冷却方式是经由过程向呆板内吹入冷空气。但仅仅依赖冷空气不足以带走云云年夜量的热量,
高机能、计较密集型的呆板必需利用流经冷却板的液体来散热。液体接收的热量必需经由过程其他路子披发出去,凡是是经由过程安装于修建物屋顶的年夜型空调机组披发到空气中。有用的热治理解决方案,例如进步前辈的冷却技能及高导热性质料,对于在维持高机能计较体系的机能及靠得住性至关主要。
高带宽需求
正如前例所示,虽然 2.5D 集成有助在提供局部带宽,但现代体系范围重大,需要年夜量此类高度集成的超等芯片。是以,于这些体系之间举行信息通讯至关主要。人工智能练习模子必需处置惩罚海量数据,而高速互连(例如英伟达 B200 体系中利用的互连)于促成计较单位及内存之间快速传输数据方面阐扬着要害作用。
传统上,机架中芯片之间的通讯是经由过程嵌入芯片毗连板中的电线实现的。跟着通讯速度的不停提高,传统电气互连的物理限定已经成为提高带宽的重要障碍之一。
为了降服从一个板上的芯片到另外一个板上的芯片之间通讯的带宽限定,研究职员正于开发“飞线”毗连器。这些毗连器直接位在超等芯片的顶部,使高机能电缆可以或许直接毗连到芯片,而电缆的另外一端则直接毗连到另外一块电路板上的毗连器。该电缆的设计旨于实现最 佳的旌旗灯号传输机能。研究职员正于实验电缆及光缆,以期将接口速率晋升到今朝每一根线缆每一秒 1000 亿比特以上的程度。
存储技能成长
存储技能连续演进,重叠技能及新质料方面不停涌现立异结果。例如,重叠多层闪存(即断电后仍能连结数据完备性的存储器)等技能冲破了现有技能的局限,实现了更高的存储密度及更优秀的机能。这些前进对于在满意现代运用(从人工智能到年夜数据阐发)日趋增加的数据需求至关主要。
动态随机存取存储器 (DRAM) 及闪存技能最近几年来均取患了显著进展,但随之而来的制造成本增长象征着每一比特成本的晋升幅度有限。3D)布局(例如垂直 DRAM 晶体管)的开发降服了传统平面晶体管的物理限定,从而实现了存储密度的连续晋升。三维封装技能使患上出产具备更高容量及更高机能的存储器件成为可能,这些器件被称为高带宽存储器 (HBM)。
动态随机存取存储器 (DRAM) 及闪存技能最近几年来都取患了显著前进,但随之而来的制造成本增长象征着每一比特成本的改善幅度有限。DRAM 及闪存早于几十年前就已经转向三维布局,而且为了扩大存储单位尺寸,不能不采用愈来愈繁杂的布局。芯片重叠技能也已经被广泛运用多年,以增长单个封装中存储的比特数。近期发生变化的是高密度内存 (HBM) 市场的增加。这种存储器需要一种更繁杂的芯片重叠技能,称为硅通孔 (TSV),该技能需要很多导线垂直穿过芯片。
跟着存储技能的范围不停扩展,连结机能及靠得住性变患上愈来愈具备挑战性。对于在DRAM而言,泄电流及量子效应等问题限定了电容器及晶体管的可扩大性。为了应答这些挑战,研究职员开发了进步前辈的制造技能,用在创立繁杂的3D布局,从而于连结所需电气特征的同时提高存储密度。
人工智能计较的蓬勃成长也影响了DRAM行业。如今专用呆板进修体系强盛的计较能力象征着需要每一秒处置惩罚海量数据,即数据带宽,才能满意其运行需求。这类对于高带宽内存的需求催生了前文提到的HBM市场。是以,最初唯 一的HBM制造商——韩国海力士公司(Hynix)已经成长成为最 年夜的DRAM制造商,逾越了多年来一直引领市场的三星。中国也对于DRAM及闪存出产举行了年夜量投资。
一样,最多见的闪存类型——NAND闪存——于2010年月中期过渡到3D单位设计,并于已往十年中经由过程增长3D晶体管重叠的层数来提高密度。然而,这类要领需要繁杂的制造工艺来确保终极存储器件的靠得住性及机能。
磁阻随机存取存储器(MRAM)及相变存储器(PCM)等新兴存储技能也正逐渐成为现有嵌入式非易掉性存储技能的替换方案。这些技能于速率、经久性及能效方面具备上风,使其成为传统嵌入式非易掉性存储解决方案的抱负替换方案。(非易掉性存储器纵然于断电后也能保留其内容。)
内存技能的进一步立异对于在鞭策数据密集型运用的连续增加至关主要。从人工智能练习模子到云计较及年夜数据阐发,现代运用都需要年夜量的内存来高效地存储及处置惩罚数据。
瞻望将来
于人工智能(特别是呆板进修)及高机能计较日趋增加的需求鞭策下,半导体行业有望于将来几年取患上庞大进展。诸如2.5D集成、芯片组及光子互连等新技能的引入,估计将于满意这些需求方面阐扬要害作用。这些立异将有助在晋升机能、增长带宽并提高能效,从而降服传统半导体设计的局限性。新兴的存储技能及进步前辈的制造工艺对于在行业成长也至关主要。存储器重叠及与处置惩罚器集成方面的立异将提高数据传输速率并降低延迟,从而满意现代运用日趋增加的数据需求。进步前辈质料及晶体管架构的开发将进一步拓展半导体的机能极限,实现连续的小型化及机能晋升。
三维异构集成
如上所述,进步前辈的芯片设计有时会采用三维布局。今朝,这些设计仅限在一些特定运用范畴,例如高密度内存(HBM)及高机能计较。这些三维布局源在一种称为三维异构集成的制造技能。这与2.5维集成差别,后者是将差别的芯片单位放置于统一基板上。真实的三维异构集成是一种半导体系体例造技能,它触及将差别的电子元件(例如处置惩罚器及存储器)垂直重叠,并于它们之间举行垂直互连。异构性象征着这些重叠的组件可使用差别的质料及工艺制造,并针对于其特定功效举行优化。
例如,采用一种制造工艺制造的处置惩罚器可以与采用另外一种制造工艺制造的存储器重叠于一路,每一个组件都利用最合适其用途的技能。这类要领有望经由过程缩短组件间的数据传输间隔来晋升机能及效率,使器件速率更快、体积更小——只管价钱是制造工艺越发繁杂,且芯片散热难度更年夜。
要使三维异构集成获得更广泛的运用,需要降服诸多挑战。这些挑战包括热治理、机械应力及靠得住性、制造繁杂性及成本、互连靠得住性以和设计繁杂性。很多此类问题也存于在传统的二维及2.5维集成中,但垂直重叠会孕育发生一些于传统二维芯片中不存于或者严峻水平低患上多的新型妨碍模式。
光子链路及组件
高机能电旌旗灯号传输链路的传输间隔跟着数据带宽的增长而不停缩短。光子(光)链路此刻被用在更远间隔的通讯。光子学是电子学的光学模仿——电子学利用电子举行旌旗灯号传输及信息承载,而光子学则利用光子(光)来实现不异的目的。诸如硅光子学等立异技能的呈现,使患上光子链路于更短的间隔上也极 具吸引力,包括一些芯片间的通讯。
硅光子链路有望降低数据中央及还没有采用光子技能的长间隔数据传输的能耗,并提高带宽。此外,它们可以于单根光纤上同时处置惩罚差别的波长。这加强了数据传输容量,使光子技能成为高机能计较及数据中央运用的抱负解决方案。经由过程用光互连代替电互连,数据中央可以削减数据传输所需的能量,从而降低运营成本并削减情况萍踪。光子学的这些上风一直是该范畴研究的驱动力,但最近几年来对于高耗强人工智能运用的需求激增,进一步鞭策了此类研究。
因为质料不相容,将光子器件与硅基技能集成极 具挑战性;例如,高效的发光质料(如 III-V 族半导体)与硅的集成效果欠安。(III-V 族半导体由硼、铝、镓或者铟与氮、磷、砷或者锑联合而成。)硅虽然合用在光探测器,但其发光效率低下,这使患上于芯片或者电路板层面实现这些技能的可扩大集成变患上繁杂。降服这些挑战对于在充实阐扬光子链路于年夜范围、低能耗运用中的潜力至关主要。
运用特定优化
跟着摩尔定律靠近极限,将来计较技能的前进将更多地依靠在针对于特定运用的算法、硬件及技能的优化,而非通用技能的扩大。这需要从质料到设计要领的整个技能栈举行立异。然而,业界面对着一个悖论:对于倾覆性立异的需求与芯片开发的昂扬成本及漫长周期相冲突,芯片开发成本可能跨越1亿美元,耗时两年以上。
为相识决这个问题,业界必需让体系设计摸索越发便捷、经济及高效。研究职员正于努力确保对于芯片的特定设计变动无需从头设计整个芯片。解决方案包括使软件设计职员可以或许于无需深切相识硬件的环境下测试定制加快器,以和开发供给用步伐开发职员对于基础平台举行小型硬件扩大的东西。这类要领于首届斯坦福新兴技能评论(SETR 2023)中有更具体的描写,它依靠在重要科技公司的介入,这些公司需要介入近似运用市肆的硬件定制模式,以均衡开放式立异及盈利念头。
【本文由投资界互助伙伴微信公家号:半导体行业不雅察授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-雷火·竞技