


首页财产阐发评论投资正文 烦人的内存墙 最近几年练习进步前辈Transformer模子计较成本剧增,硬件峰值FLOPS增速远超DRAM及互连带宽,内存成瓶颈,需从头思索模子练习、部署、设计和硬件应答计谋。 2026-02-02 11:05 ·微信公家号:半导体行业不雅察arXiv arXiv AI投资人解读· 已往20年办事器硬件峰值FLOPS增速远超DRAM及互连带宽,内存成人工智能运用瓶颈。以GPT-2为例,自回归推理因内存操作量高、算术强度低,致使延迟较着善于BERT-Base等模子。 · 练习要领效率低、超参数调优繁杂、模子部署坚苦,且硬件加快器偏重晋升计较能力,对于内存密集型事情负载存眷少。 总结:内存瓶颈限定人工智能成长,需从头思索模子练习、部署及设计,以和硬件应答计谋,如采用高效算法、优化模子部署、改良加快器设计等。内容由AI天生,仅供参考 史无前例的无监视练习数据的可用性,以和神经收集的扩大纪律,致使用在办事/练习低层逻辑模子(LLM)的模子范围及计较需求呈现了史无前例的激增。然而,重要的机能瓶颈正日趋转移到内存带宽上。
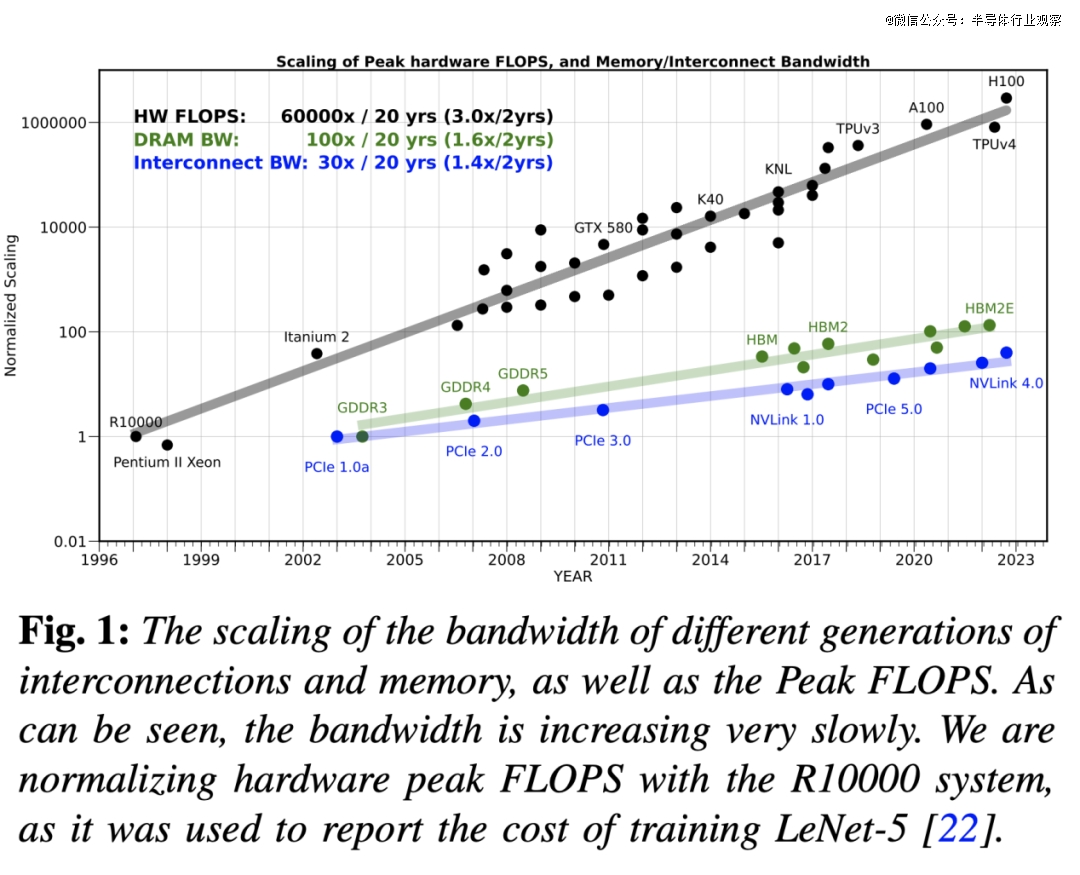
已往20年,办事器硬件的峰值浮点运算能力(FLOPS)以每一两年3倍的速率增加,跨越了DRAM及互连带宽的增加速率,后二者别离仅以每一两年1.6倍及1.4倍的速率增加。这类差距使患上内存而非计较成为人工智能运用(特别是办事运用)的重要瓶颈。
本文阐发了编码器及解码器Transformer模子,并展示了内存带宽怎样成为解码器模子的重要瓶颈。咱们提出从头设计模子架构、练习及部署计谋,以降服这一内存限定。
弁言
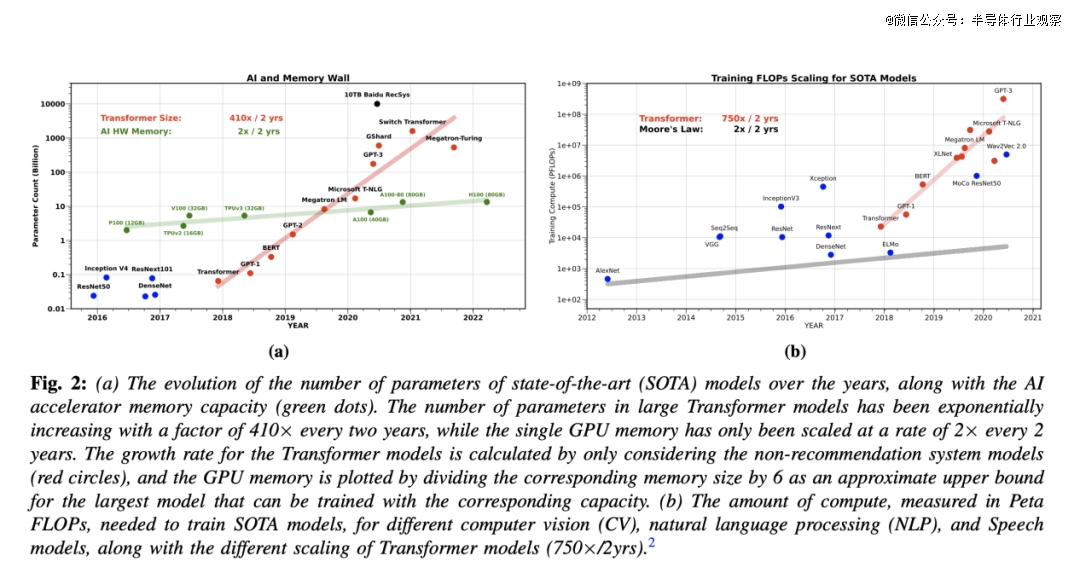
最近几年来,练习年夜型语言模子 (LLM) 所需的计较量以每一两年 750 倍的速率增加。这类指数级增加趋向是人工智能加快器成长的重要驱动力,这些加快器致力在晋升硬件的峰值计较能力,但往往以捐躯其他部门(例如内存条理布局)的简化为价钱。
然而,这些趋向纰漏了练习及办事人工智能模子历程中一个新兴的挑战:内存及通讯瓶颈。事实上,很多人工智能运用的瓶颈并不是计较能力,而是芯片内部/芯片间以和与人工智能加快器之间/芯片间的通讯。这并不是新征象,已往的一些研究已经经不雅察到并正告了这个问题。最早对于此的不雅察可以追溯到 1990 年,其时 Ousterhout 于阐发影响操作体系机能的因素后患上出如下结论:
“第 一个与硬件相干的问题是内存带宽:基准测试注解,内存带宽跟不上 CPU 的速率……假如将来的呆板内存带宽没有显著提高,某些类型的运用步伐可能会遭到内存机能的限定。”
1995 年晚些时辰,William Wulf 及 Sally Mckee 进一步呼应了这一猜测,并创造了“内存墙”(memory wall)一词。他们的论证遵照一个简朴而精妙的逻辑。完成一项操作所需的时间取决在咱们履行算术运算的速率以和咱们向硬件运算单位提供数据的速率。¹于最简朴的环境下,数据要末于缓存中可用,要末需要从 DRAM 中获取。基在此假定,纵然 80% 的数据可以直接于缓存中获取,只有 20% 的数据需要从 DRAM 中获取,假如从 DRAM 中获取这 20% 的cache-miss数据需要跨越 5 个时钟周期,那末完成操作所需的时间将彻底受限在 DRAM。这象征着,不管硬件每一秒履行的算术运算速率有多快,问题都将彻底受限在 DRAM 带宽。
他们猜测,计较速率的晋升速率与数据获取速率的晋升速率呈现不合,将会致使“内存墙”问题。基在此,他们患上出如下结论:
“二者的机能都于呈指数级增加,但微处置惩罚器的机能增加指数弘远在DRAM。并且,差别指数级增加之间的差异也于呈指数级增加。”
厥后的几篇文献也报导了近似的不雅察成果。
于这项事情中,咱们经由过程研究更新的数据从头审阅了这一趋向,特别存眷用在练习人工智能模子的硬件,以和用在练习/运行这些模子的计较特征。30 年已往了,上述不雅察及猜测依然彻底准确。只管内存技能取患了诸多立异,但趋向注解,“内存墙”正日趋成为一系列人工智能使命的重要瓶颈。
咱们起首阐发自 1998 年 Yann Lecun 于 MNIST 数据集上练习出闻名的 Lenet-5 模子以来,办事器级 AI 硬件的峰值计较能力发生了如何的变化。咱们可以看到,已往 20 年间,硬件的峰值计较能力增加了 6 万倍,而 DRAM 的峰值计较能力仅增加了 100 倍,互连带宽也仅增加了 30 倍。
内存墙问题触及内存容量及带宽的限定,以和内存传输的延迟(延迟的改良难度甚至比带宽更年夜)。这触及到差别层级的内存数据传输。例如,计较逻辑与片上内存之间的数据传输,计较逻辑与 DRAM 内存之间的数据传输,以和差别插槽上差别处置惩罚器之间的数据传输。于所有这些环境下,数据传输的容量及速率都显著掉队在硬件的计较能力。
此刻,假如咱们研究近期人工智能模子(特别是LLM)的成长趋向,咱们会发明,受神经收集扩大定律的开导,从业者们之前所未有的速率扩大了练习这些模子所需的数据量、模子范围及计较资源。只管于2018年至2022年时期,练习这些模子所需的计较量/浮点运算次数(FLOPs)增加了750倍/两年(见图2),但计较资源未必是瓶颈,特别是于模子办事方面。
起首,LLM的范围于此时期以410倍/两年的速率增加,跨越了单个芯片的可用内存。人们也许会但愿,咱们可以经由过程将练习/办事扩大到多个加快器来实现漫衍式内存并行,从而防止单个硬件内存容量及带宽的限定。然而,将事情分配到多个进程也可能面对内存墙问题:神经收集 (NN) 加快器之间数据传输的通讯瓶颈,其速率甚至比片上数据传输更慢、效率更低。与单体系内存的环境近似,咱们还没有能降服扩大收集带宽的技能挑战。
其次,纵然模子可以或许装入单个芯片,芯片内部寄放器、L2 缓存、全局内存等之间的数据传输仍旧日趋成为瓶颈。患上益在专用计较单位(例如 Tensor 焦点)的最新进展,年夜量计较的算术运算可以于几个周期内完成。是以,为了始终连结这些算术单位的使用率,需要快速地向其提供年夜量数据,而这恰是芯片内存带宽成为瓶颈之处。
如图 1 所示,已往 20 年间,办事器硬件的峰值浮点运算能力 (FLOPS) 以每一两年 3.0 倍的速率增加,远超 DRAM 及互连带宽的增加速率(后二者别离仅以每一两年 1.6 倍及 1.4 倍的速率增加)。这类差距使患上内存而非计较能力日趋成为瓶颈,纵然于模子可以或许容纳在单个芯片的环境下也是云云。
接下来,咱们将对于 Transformer 举行具体的案例研究,经由过程考查现今经常使用的模子,更好地展示浮点运算能力 (FLOPS)、内存操作 (MOP) 及端到端运行时间之间的彼此作用。
案例研究
于本节中,咱们起首概述Transformer推理的运行时特征及机能瓶颈。咱们考查Transformer架构的两种差别变体:编码器架构(例如BERT),它并发处置惩罚所有tokens;以和解码器架构(例如GPT),它以自回归的方式运行,每一次迭代处置惩罚并天生一个token。
A.
算术强度(Arithmetic Intensity)
权衡机能瓶颈的一种经常使用要领是计较仅计较 Transformer 编码器及仅计较解码器模子所需的总 FLOP 数。然而,零丁利用这一指标可能会孕育发生很年夜的误导。是以,咱们需要研究相干操作的算术强度。算术强度是指从内存加载的每一个字节可以履行的 FLOP 数。它可以经由过程将总 FLOP 数除了以拜候的总字节数(也称为 MOP,即内存操作数)来计较。
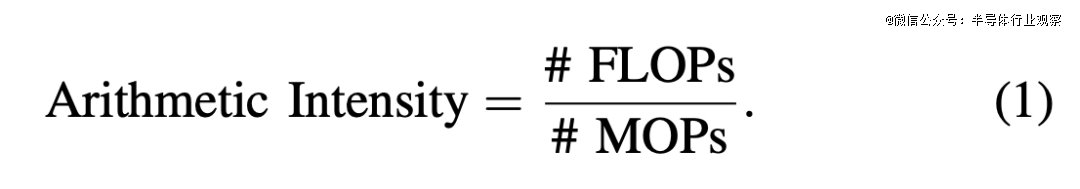
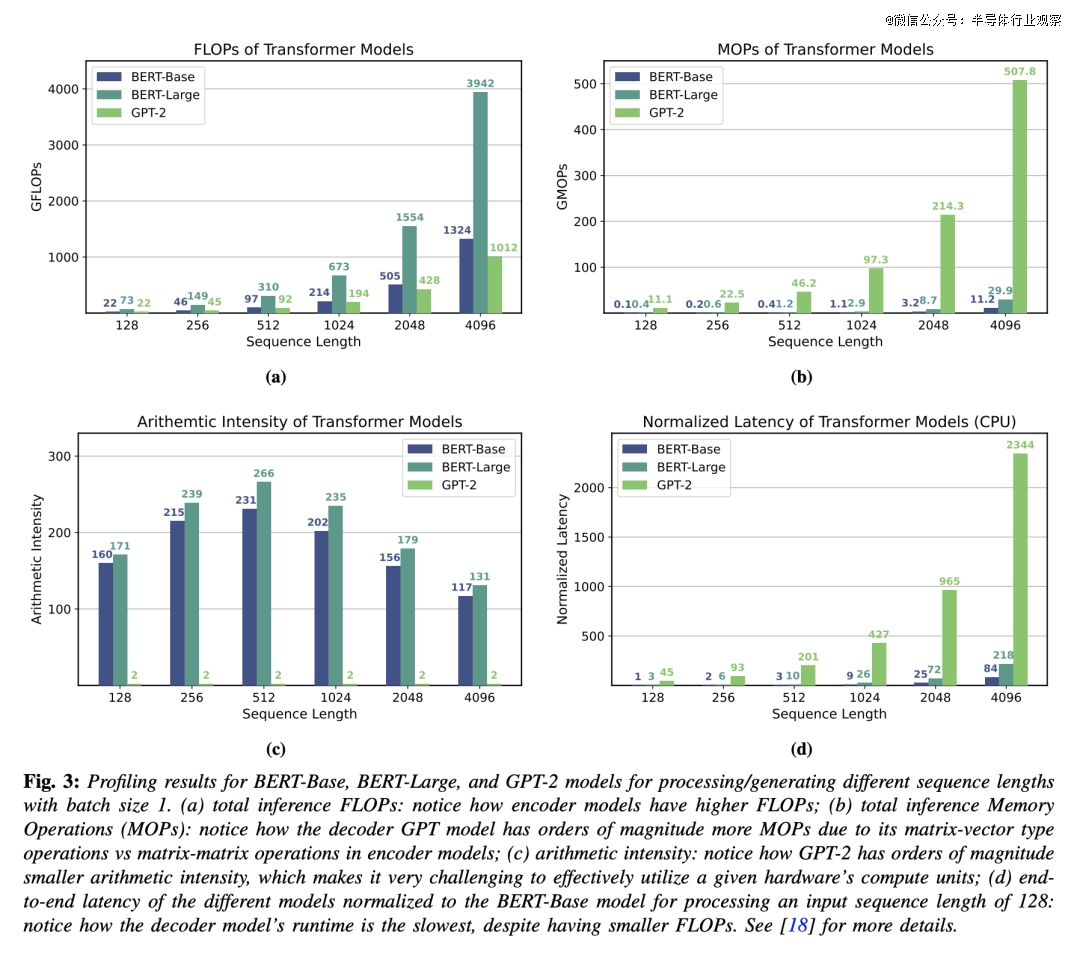
为了申明思量算术强度的主要性,咱们研究了 BERT-Base 及 BERT-Large 以和 GPT-2 。前二者是编码器模子,其推理触及矩阵-矩阵运算;后者是解码器/自回归模子,其推理触及反复的矩阵-向量乘法。
B.
机能阐发
为了阐发 Transformer 事情负载于通用硬件上的瓶颈,咱们于 Intel Gold 6242 CPU 上对于 Transformer 推理举行了机能阐发。图 3 显示了差别序列长度下这些模子的总 FLOPs、MOPs、算术强度及终极延迟。显然,对于在每一种序列长度,GPT-2 的延迟都较着善于 BERT-Base 或者 BERT-Large,纵然 BERT-Base 及 GPT-2 的模子配置及端到端 FLOPs 基真相同(如图 3a 所示)。这是因为 GPT 的自回归推理固有的矩阵向量运算具备更高的内存操作量及更低的算术强度(见图 3c)。算术强度更高的模子于不异甚至更高的 FLOPs 下可以比算术强度更低的模子运行患上更快。这清晰地注解,内存墙怎样成为解码器模子(于小批量巨细下)的重要瓶颈,而不是计较瓶颈。
冲破内存瓶颈的有但愿的解决方案
“指数增加不成能永远连续下去”[,纵然对于在年夜型超年夜范围公司而言,以 410 倍/2 年的速率延迟指数级扩大也并不是恒久之计。此外,计较能力及带宽能力之间的差距日趋扩展,这将很快使练习年夜型模子变患上极 具挑战性,由于成本将呈指数级增加。
为了继承立异并冲破内存瓶颈,咱们需要从头思索人工智能模子的设计。这里存于几个问题。
起首,当前设计人工智能模子的要领年夜可能是姑且性的,或者者只触及很是简朴的扩大法则。例如,近来呈现的年夜型 Transformer 模子年夜多只是对于最初 BERT 模子中提出的险些不异的基础架构举行缩放。
其次,咱们需要设计更高效的人工智能模子练习要领。今朝的神经收集需要年夜量的练习数据及数十万次的迭代才能进修,效率很是低下。有人可能会指出,这与人脑的进修方式也差别,人脑凡是每一个观点/种别只需要少少的例子。
第三,当前的优化及练习要领需要年夜量的超参数调优(例如进修率、动量等),这凡是会致使数百次的试错,才能找到适合的超参数设置来乐成练习模子。是以,图 2 (b) 中陈诉的练习成本只是现实开消的下限,而现实成本凡是要高患上多。
第四,最 进步前辈模子的重大范围使患上它们难以部署用在推理。这不仅限在 GPT-3 等模子。事实上,部署超年夜范围公司利用的年夜型保举体系也是一项庞大挑战。
末了,硬件加快器的设计重要集中于提岑岭值计较能力,而对于改善内存密集型事情负载的存眷相对于较少。这使患上练习年夜型模子以和摸索替换模子(例如图神经收集)都变患上坚苦,由于图神经收集凡是受限在带宽,没法有用地使用当前的加快器。
以上所有问题都是呆板进修范畴的底子性难题。本文将扼要会商近期针对于后三项问题的研究(包括咱们自身的研究)。
A.
高效练习算法
练习神经收集模子的重要挑战之一是需要举行年夜量的超参数调优。这包括确定进修率、退火计谋、收敛所需的迭代次数等等。这会给练习最 进步前辈的模子带来(显著的)分外开消。很多此类问题源在用在练习的一阶随机梯度降落(SGD)要领。虽然SGD的变体易在实现,但它们对于超参数调优的鲁棒性较差,而且对于在未知最 佳超参数集的新模子,很难举行调优。一种颇有远景的解决要领是利用二阶随机优化要领。这些要领凡是对于超参数调优更具鲁棒性,而且可以到达最 进步前辈的程度。然而,当前要领的内存占用量是其他要领的3-4倍,这需要加以解决。微软的 Zero 框架于这方面揭示出优良的远景,它经由过程移除了/分片冗余的优化状况变量,展示了怎样于内存容量稳定的环境下练习范围扩展 8 倍的模子。假如可以或许解决这些高阶要领的开消问题,那末它们就能显著降低练习年夜型模子的总成本。
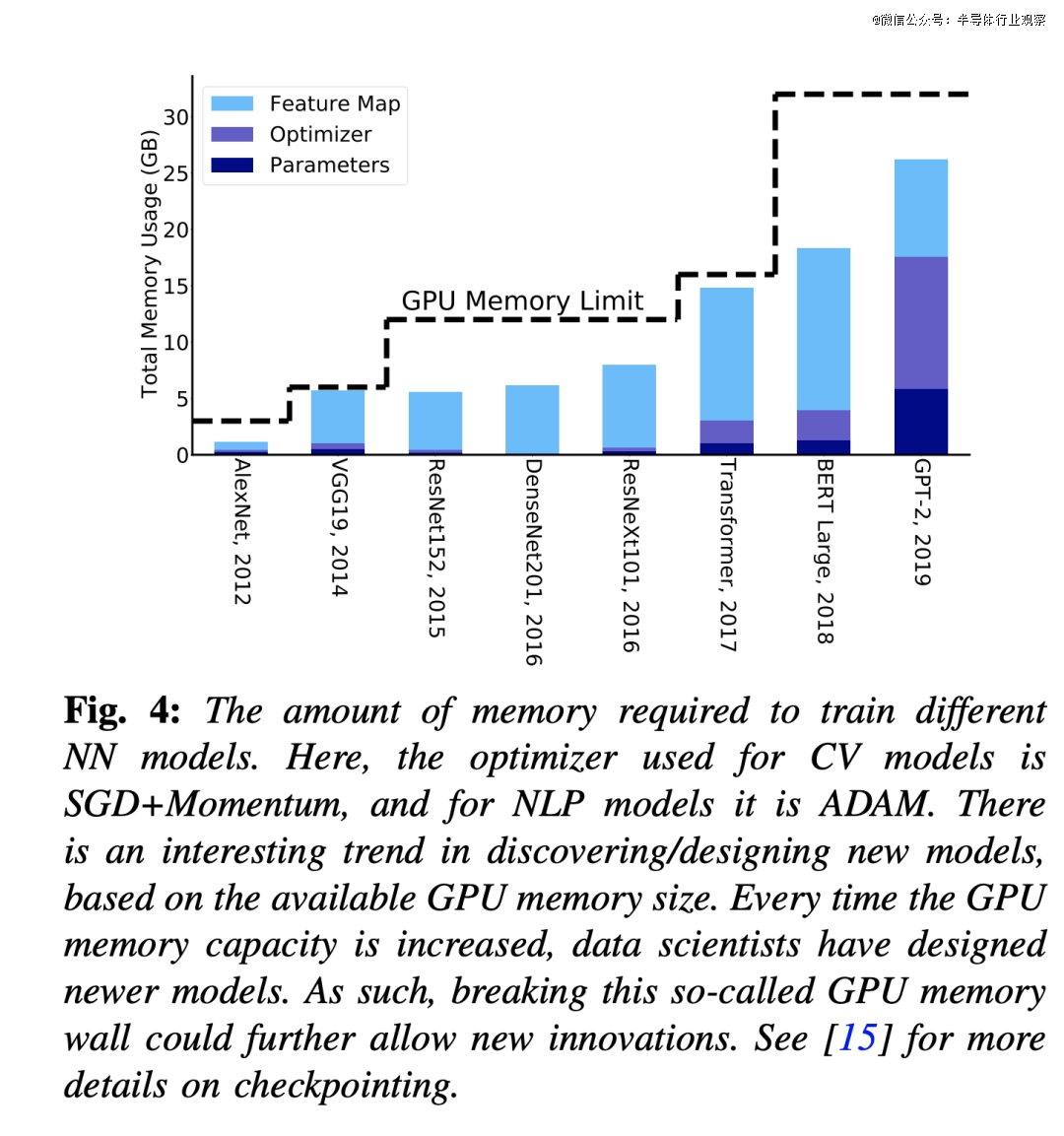
另外一种颇有远景的要领是削减内存占用并提高优化算法的数据局部性,但价钱是需要履行更多计较。数值线性代数中一个显著的例子是通讯防止算法族。神经收集练习中内存优化的一个例子是重物化,即于前向流传历程中只存储/查抄点一部门激活值,而不是生存所有激活值。如图4所示,这削减了特性图的内存占用。其余的激活值可以于需要时从头计较。只管这会增长计较量,但只需增长20%的计较量,就能够显著削减高达5倍的内存占用。这还有可让开发者于单芯片内存上练习年夜型模子,而无需利用漫衍式练习。漫衍式练习凡是难以设置(年夜型超年夜范围数据中央公司除了外),并且对于在非专业开发者来讲也难以调试。
有趣的是,传统趋向注解,新的神经收集模子架构的开发是基在研究职员于单个芯片内可拜候的资源,而不是利用繁杂的漫衍式内存要领(见图 4)。固然,也有很多反例,例如年夜型超标量计较机拥有专门的团队来撑持研究职员部署年夜型模子,但当咱们思量整个社区时,这种例子就比力有限了。事实上,纵然是最新的初级内存模子,也经常需要投入年夜量精神来压缩模子,使其可以或许顺应单个体系,从而使更广泛的研究职员群体可以或许拜候这些模子。
另外一个主要的解决方案是设计对于低精度练习具备鲁棒性的优化算法。事实上,人工智能加快器范畴的一项庞大冲破是利用半精度 (FP16) 运算,而非单精度运算 。这使患上硬件计较能力晋升了 10 倍以上。然而,于不降低精度的环境下,使用当前的优化要领进一步降低精度(从半精度到 INT8)一直是一个挑战。一个近期颇有远景的趋向是混淆利用 FP8 及 FP16(甚至近来的 FP4)。该范畴的算法立异无疑将使咱们可以或许更有用地使用硬件,并答应芯片的更多区域用在晋升内存机能(这凡是被称为内存间隙处罚 )。
B.
高效部署
部署最新的最 进步前辈模子或者年夜型保举体系极 具挑战性,由于它们需要漫衍式内存部署来举行推理。一个颇有远景的解决方案是压缩这些模子以举行推理,可以经由过程降低精度(即量化)、移除了(即剪枝)其冗余参数或者设计小型语言模子来实现。
第 一种要领是量化,它可以运用在练习及/或者推理阶段。虽然将练习精度降低到远低在 FP16 很是具备挑战性,但可使用超低精度举行推理。使用现有要领,将推理精器量化到 INT4 相对于轻易,且瞄准确率的影响极小。这可使模子占用空间及延迟至多降低 8 倍。然而,利用低在 INT4 的精度举行推理更具挑战性,今朝这是一个很是活跃的研究范畴。
第二种要领是剪枝,它可以彻底移除了/剪枝模子中的冗余参数。使用现有要领,可以剪枝高达 30% 的布局化稀少神经元,以和高达 80% 的非布局化稀少神经元,且瞄准确率的影响极小。然而,冲破这个限定很是具备挑战性,而且凡是会致使严峻的正确率降落。解决这个问题仍是一个开放性问题。
第三种要领,即小型语言模子,有望斥地全新的范畴,并鞭策人工智能的广泛运用。有趣的是,自 2017 年 Transformer 模子问世以来,用在语言进修模子 (LLM) 的模子自己并无转变。今朝行之有用的要领是扩大数据范围及模子巨细,这促进了这些模子的“涌现能力” 。然而,近期关在小型语言模子的研究已经揭示出使人鼓动的结果。假如一个模子可以或许彻底集成到芯片上,那末速率晋升及能耗降低都将到达几个数目级。
C.
从头思索人工智能加快器的设计
同时晋升芯片的内存带宽及峰值计较能力面对着底子性的挑战。然而,捐躯峰值计较能力可以换取更好的计较/带宽衡量。事实上,CPU架构已经经集成为了一个颠末充实优化的缓存条理布局。这就是为何CPU于带宽受限问题上比GPU机能更优的缘故原由。
这种问题包括年夜型保举问题。然而,今朝CPU面对的重要挑战是其峰值计较能力(即FLOPS)比GPU或者TPU等人工智能加快器低一个数目级。造成这类环境的缘故原由之一是,人工智能加快器的设计重要方针是实现最 年夜的峰值计较能力。这凡是需要移除了缓存条理布局等组件,以增长计较逻辑。咱们可以假想一种介在这两种极度环境之间的替换架构,最 好具备更高效的缓存,更主要的是,具备更高容量的DRAM(多是一个具备差别带宽的DRAM条理布局)。后者对于在减缓漫衍式内存通讯瓶颈可能很是有帮忙。
结论
最近几年来,练习最 进步前辈的天然语言处置惩罚(NLP)Transformer模子的计较成本以每一两年750倍的速率增加,模子参数范围以每一两年410倍的速率增加。比拟之下,硬件峰值浮点运算能力(FLOPS)以每一两年3.0倍的速率增加,而DRAM及互连带宽的增加速率却日趋滞后,别离以每一两年1.6倍及1.4倍的速率增加。
为了更直不雅地舆解这些数字,咱们可以对于比一下:已往20年,硬件峰值浮点运算能力增加了6万倍,而同期DRAM及互连带宽的增加速率别离仅为100倍及30倍。根据这类趋向,内存——特别是芯片内/芯片间内存传输——将很快成为年夜型人工智能模子的重要瓶颈。
是以,咱们需要从头思索人工智能模子的练习、部署及设计,以和怎样设计人工智能硬件来应答日趋严重的内存墙挑战。

【本文由投资界互助伙伴微信公家号:半导体行业不雅察授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-雷火·竞技